염산하
claude.ai 의 프로젝트는 프로젝트 내의 다른 대화를 참조할 수 있는데 자동식이 아니라 수동식이다. 내가 과거 대화를 찾아보라던가 이전의 이런 대화를 어쩌고 하는 식으로 명시적 요청이 있을 때 검색해보고 사용하는 식. 제어 가능하고, 과거 대화가 새 대화에 미묘하게 영향을 주지 않아서 좋은 방식이라고 느꼈다.
@[email protected] · 23 following · 15 followers
A software engineer in Seoul, and a father of a kid.
claude.ai 의 프로젝트는 프로젝트 내의 다른 대화를 참조할 수 있는데 자동식이 아니라 수동식이다. 내가 과거 대화를 찾아보라던가 이전의 이런 대화를 어쩌고 하는 식으로 명시적 요청이 있을 때 검색해보고 사용하는 식. 제어 가능하고, 과거 대화가 새 대화에 미묘하게 영향을 주지 않아서 좋은 방식이라고 느꼈다.
워싱턴포스트에 한국 인터넷 성인만화광고 문제를 지적한 컬럼이 올라왔다. https://www.washingtonpost.com/world/2025/09/26/webtoon-online-ads-explicit-violence/
뉴스 기사 같은 일반 사이트에서도 '여성이 남성의 성폭행으로부터 도망치는 장면' 같은 성폭력적인 내용의 웹툰 광고가 버젓이 나오는데, 기사에서는 여러 회사나 단체가 언급되지만 누구에게 책임이 있는지는 잘 드러나지 않는다. 성인웹툰 회사들은 "개선하고 있다" 같은 원론적 답변만 내놨고.
#cosmoslide 작업 내역
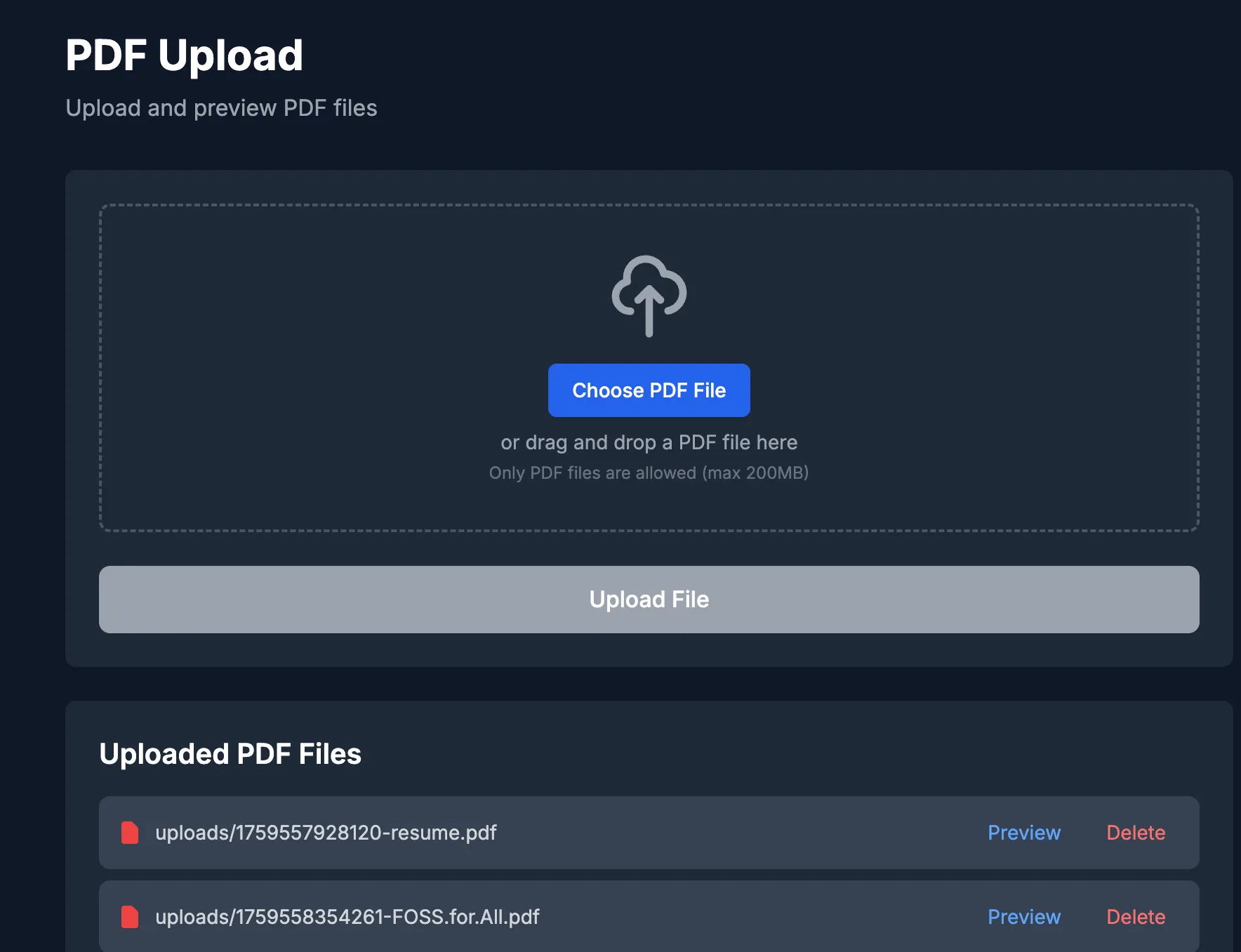
https://github.com/cosmoslide/cosmoslide/pull/45 PDF 업로드 기능이라도 구축은 해야할 것 같아서 진행함. 보통은 express라던가 등등 JS 기반의 웹서버 프레임워크에서는 파일시스템/S3/GCS 등의 스토리지에 파일을 업로드할때, 스토리지에 접근하는 과정 자체를 추상화하는 flydrive라는걸 쓰는데, flydrive는 NestJS에서 사용이 되지 않는 ESM-only 모듈이어서, 어떻게 해야 하나 하다가 Claude Code한테 AWS S3에 접근하는 것만 적당히 추상화해서 야크쉐이빙 해달라고 했더니 그냥 순식간에 되었다. 문서를 뜯어보고 구현해야하는 수고는 줄었고, aws sdk를 어떻게 활용하는지는 가성비있게 학습할 수 있는 기회가 되었다.
https://github.com/cosmoslide/cosmoslide/pull/46 프로필 화면에 Presentation 탭을 넣었고, 프레젠테이션 파일을 업로드하면 Create(Note) 액티비티가 발생되도록 처리했다. react-pdf 이용해서 커스텀 PDF 뷰어 적당히 끼워넣었다.

@[email protected] · Reply to 염산하's post
아이폰에서 웹앱 형태로 설치했던 phanpy 는 로컬데이터 지우는 방법 찾기 귀찮아서 그냥 지우고 웹 브라우저 바로가기 형태로 변경했다.
@[email protected] · Reply to 푸른곰's post
@purengom 많이 쓰시네요 ㅎㅎㅎ 혹시 어디 쓰시나요? ^^
배외 감정에 대한 통계가 기억나지는 않지만 지난 대선에서 조사된 2030남성 보수 지지층이 대부분 고학력자들이라는 통계와는 충돌하는 주장이라고 생각됨.
https://x.com/stingraykite/status/1974155607822516566?s=46&t=3SSCMzU8n1YA4_S4Nc9Piw
hollo 0.6.12 로 업그레이드 성공! phanpy.social 은 수작업으로 로컬에 생긴 모든 데이터를 일일이 지워줘야 잘 되는 듯.
https://hollo.social/@hongminhee/0199aab3-d7c3-7e81-8ecb-e374ec6738a7

@[email protected] · Reply to 洪 民憙 (Hong Minhee) :nonbinary:'s post
#Hollo 쓰시는 분들은 可能한 限 빨리 0.6.12 버전으로 올리시기 바랍니다. DM이 公開 揭示物 페이지에서 露出되는 深刻한 保安 脆弱點이 패치되었습니다.
https://hollo.social/@hollo/0199aaaf-7979-7da3-9509-73c9e487de05
@[email protected] · Reply to 洪 民憙 (Hong Minhee) :nonbinary:'s post
#Hollo 쓰시는 분들은 可能한 限 빨리 0.6.12 버전으로 올리시기 바랍니다. DM이 公開 揭示物 페이지에서 露出되는 深刻한 保安 脆弱點이 패치되었습니다.
https://hollo.social/@hollo/0199aaaf-7979-7da3-9509-73c9e487de05

We've released #Hollo 0.6.12 to fix a critical privacy #vulnerability where direct messages were being exposed in the replies section of public posts. Please update your instances immediately to ensure your private conversations remain private.
@[email protected] · Reply to 洪 民憙 (Hong Minhee) :nonbinary:'s post
@hongminhee 호옥시 0.5 계열도 올려야할까요?
:terminal 커맨드를 사용하면서 알게 된 내용
:terminal excommand는 buftype이 'terminal'인 buffer를 연다
Terminal-Job 모드와
vim-keybinding을 사용할 수 있는 Terminal-Normal 모드를 지원한다.Terminal-Job모드에서 Terminal-Normal모드로 전환은 키를 이용한다. (:h terminal-typing)
<C-\><C-N><C-W>N(CTRL-W 입력 후 그냥 대문자 N을 입력):terminal로 진입하면 기본적으로 Terminal-Job모드로 설정된다.Terminal-Job모드에서 인터랙티브 셸을 종료하면 해당하는 terminal buffer가 닫힌다.Terminal-Job모드는 tmap을 이용하여 제어할 수 있다.
tmap jj <C-W>N은 imap jj <ESC> 만큼 유용하다
less 바인딩에서 네비게이팅하기 어려워 별도의 키바인딩을 사용하는게 좋다.
tnoremap <C-Q> <C-W>Ntnoremap <C-S-V> <C-W>"+를 이용하여 unnamedplus 레지스터의 내용을 붙여넣는다feedkeys 함수를 이용한다
call feedkeys("i\<C-u>")
i)<C-u>)
$ bind -p | grep unix-line-discard "\C-u": unix-line-discardterminal buffer에서는 terminal-api를 이용해 vimscript를 호출할 수 있다.(:h terminal-api)
Tapi_를 prefix로 가지는 함수만 실행 가능하다Tapi_ prefix는 term_sendapi 함수를 이용해 prefix를 바꿀 수 있다:source %로 등록한다function Tapi_Test(bufnum, arglist)
echomsg a:bufnum
echomsg a:arglist
endfunction:terminal로 Terminal-Job모드에서 다음을 실행시킨다.$ printf '\e]51;["call","Tapi_Test","asdf"]\x07' :messages에서, bufnum과 arglist가 제대로 출력되었는지 확인한다.terminal-api는 이렇게 사용 방법이 복잡하고 8.2 버전 이상부터 지원되었기 때문에 가장 접근성 및 인지도가 떨어지는 기능 중 하나라고 생각한다.
terminal-api는 사용하는 방법이 매우 복잡하고, help 문서에 실사용 예시 지원이 부족하다terminal-api는 존재를 모르거나 알아도 호환성 등의 이유로 사용하지 않을 가능성이 있다.다음은 terminal-api를 이용하여 terminal-job 모드에서 파일시스템을 네비게이팅하며 terminal-job 모드의 pwd를 vim의 pwd로 sync하는 예시이다
동작원리는 다음과 같다
setbufvar를 이용하여 osc7_dir를 설정하는 terminal-api 함수를 만든다function! Tapi_SetOsc7_Dir(bufnum, arglist)
call setbufvar(a:bufnum, 'osc7_dir', a:arglist)
endfunction.bashrc에 등록한다_setosc7dir() {
printf '\e]51;["call","Tapi_SetOsc7_Dir","%s"]\x07' "$PWD" # for vim terminal api
}
alias setosc7dir="_setosc7dir"$PROMPT_COMMAND를 설정한다export PROMPT_COMMAND='setosc7dir; '"$PROMPT_COMMAND"$PROMPT_COMMAND는 모든 실행마다 추가적으로 실행되는 커맨드이므로, 무거운 작업을 등록하기 적절하지 않다.
__osc7_prev_pwd와 비교하는 로직을 추가한다__osc7_prev_pwd=""
_setosc7dir() {
if [[ "$PWD" != "$__osc7_prev_pwd" ]]; then
printf '\e]51;["call","Tapi_SetOsc7_Dir","%s"]\x07' "$PWD" # for vim terminal api
__osc7_prev_pwd="$PWD"
fi
}osc7_dir 변수가 pwd로 갱신된다cd만 호출하면 된다. 이 작업은 vim에서만 이루어진다function! SyncTerminalPwd()
let term_bufnr = bufnr()
let osc7_dir = getbufvar(term_bufnr, 'osc7_dir')
if isdirectory(osc7_dir)
echo 'osc7_dir: ' .. osc7_dir
execute 'cd ' .. osc7_dir
endif
endfunctionTerminalOpen 이벤트 autocmd에 setlocal을 이용해 키맵을 설정하자function! SetupTerminalOpen() abort
" <leader>cd : osc7_dir으로 pwd 설정
execute 'nnoremap <buffer> <leader>cd :call SyncTerminalPwd()<CR>'
endfunction
" TermOpen 이벤트에 대한 자동 명령
augroup TerminalKeymaps
autocmd!
autocmd TerminalOpen * call SetupTerminalOpen()
augroup END
:sh를 이용하여 vim의 내장 shell을 매우 적극적으로 활용했는데, 기본 동작은 vim의 pwd를 기준으로 interactive shell을 열어준다.feedkeys를 이용하여 pwd로 cd하는 명령을 보내는 것이다
getcwd로 얻을 수 있고, 터미널 버퍼에 해당 path로 cd하는 명령만 추가적으로 보내주면 된다feedkeys를 활용한다
function! OpenTerminal()
for listed_buffer in filter(getbufinfo(), 'v:val.listed')
let bufnr = listed_buffer.bufnr
let buftype = getbufvar(bufnr, '&buftype')
let buftype = (buftype == '' ? 'normal' : buftype)
if buftype == 'terminal'
execute 'buffer! ' .. bufnr
let pwd = getcwd()
" sync vim pwd
call feedkeys("i\<C-u>cd " .. pwd .. "\<CR>")
return
endif
endfor
execute 'terminal!'
endfunction물론 키바인딩도 추가한다
nnoremap <C-D> :sh<CR>를 이용하여 vim->내장 셸, 내장 셸 -> vim을 토글하는 키로 <C-D>키를 사용해 왔으므로, 터미널 버퍼로 같은 동작을 하는 키를 <C-D>로 하여 대체한다
nnoremap <C-D> :call OpenTerminal()<CR>문제는 다음과 같다
<C-D>키를 이용한 vim-셸 토글이 작동하지 않는다
Terminal-Job 모드에서 <C-D>를 입력하면 셸이 종료되며 이를 실행하던 버퍼도 같이 닫는 방식으로 동작하기 때문이다execute 'nnoremap <buffer> <C-D> :buffer! #<CR>'setlocal hiddensetlocal nonumbersetlocal nolistexecute buffer 부분에서 언제나 현재 열려있는 버퍼를 터미널 버퍼로 전환하므로, 터미널 버퍼를 다른 윈도우에 분할해서 사용하는 내 사용 방식에서는 불필요하게 두개의 윈도우가 하나의 터미널 버퍼를 연다.setbufvar로 winid를 지정해두고, 터미널 버퍼를 찾으면 먼저 해당 버퍼에 저장된 winid를 이용해 윈도우를 전환한 후 execute buffer를 실행하여 해결한다문제를 해결한 시점의 vimscript
~/.vim/autocmd/terminal.vim
function! SetupTerminalOpen() abort
let term_bufnr = bufnr()
setlocal hidden
setlocal nonumber
setlocal nolist
" <C-D> : 이전 버퍼로 전환
execute 'nnoremap <buffer> <C-D> :buffer! #<CR>'
" <leader>cd : osc7_dir으로 pwd 설정
execute 'nnoremap <buffer> <leader>cd :call SyncTerminalPwd()<CR>'
call setbufvar(term_bufnr, 'winid', bufwinid(term_bufnr)) " save winid
endfunction
" TermOpen 이벤트에 대한 자동 명령
augroup TerminalKeymaps
autocmd!
autocmd TerminalOpen * call SetupTerminalOpen()
augroup END
function! OpenTerminal()
for listed_buffer in filter(getbufinfo(), 'v:val.listed')
let bufnr = listed_buffer.bufnr
let buftype = getbufvar(bufnr, '&buftype')
let buftype = (buftype == '' ? 'normal' : buftype)
if buftype == 'terminal'
let term_winid = getbufvar(bufnr, 'winid')
if win_id2win(term_winid) != 0
" terminal buffer window is opened
" move cursor to the window
call win_gotoid(term_winid)
endif
execute 'buffer! ' .. bufnr
let pwd = getcwd()
" sync vim pwd
call feedkeys("i\<C-u>cd " .. pwd .. "\<CR>")
return
endif
endfor
execute 'terminal! ++curwin'
endfunction이정도 설정으로 잘 활용하고 있었으나, 사용 중
psql이나 python등의 REPL 프로그램을 터미널 버퍼에 실행시키고 있는 경우 해당 버퍼로 전환 할 때 마다 cd path가 입력되는 것이 불편했다g:open_terminal_mode 글로별 변수와 모드를 전환하는 키맵을 이용해 해결한다
let g:open_terminal_mode = 0
nnoremap <space><space><space> :call ToggleOpenTerminalMode()<CR>g:open_terminal_mode는 4가지 값을 가질 수 있다
:sh 사용:terminal 사용 (sync pwd):terminal 사용 (sync pwd 용 cd 명령을 보내지 않음, REPL 작업용):vsplit에서 :terminal 사용, 1회용으로 잠깐 command를 실행할 때모드 변경 및 동작방식 확인이 필요하므로 다음 help function을 추가한다
function! PrintOpenTerminalMode()
let terminal_modes = [':sh', ':terminal (cd pwd)', ':terminal', ':terminal (vs)']
let mode_repr_list = []
for idx in range(len(terminal_modes))
let t_mode = terminal_modes[idx]
if g:open_terminal_mode ==# idx
let t_mode = '< ' .. t_mode .. ' >'
endif
call add(mode_repr_list, t_mode)
endfor
echomsg join(mode_repr_list, ' | ')
endfunction
function! ToggleOpenTerminalMode()
let g:open_terminal_mode = (g:open_terminal_mode + 1) % 4
call PrintOpenTerminalMode()
endfunction
function! OpenTerminal()
call PrintOpenTerminalMode()
if g:open_terminal_mode == 0
execute ':sh'
return
endif
if g:open_terminal_mode > 0
for listed_buffer in filter(getbufinfo(), 'v:val.listed')
let bufnr = listed_buffer.bufnr
let buftype = getbufvar(bufnr, '&buftype')
let buftype = (buftype == '' ? 'normal' : buftype)
if buftype == 'terminal'
let term_winid = getbufvar(bufnr, 'winid')
if win_id2win(term_winid) != 0
" terminal buffer window is opened
" move cursor to the window
call win_gotoid(term_winid)
endif
if g:open_terminal_mode == 3 && len(getwininfo()) == 1
execute 'vsplit'
endif
execute 'buffer! ' .. bufnr
if g:open_terminal_mode == 1
let pwd = getcwd()
" sync vim pwd
call feedkeys("i\<C-u>cd " .. pwd .. "\<CR>")
endif
if g:open_terminal_mode == 3 && mode() == 'n'
call feedkeys("i\<C-u>")
endif
return
endif
endfor
if g:open_terminal_mode == 3
execute 'vsplit'
endif
execute 'terminal! ++curwin'
endif
endfunction회사에서 딴 짓하고 싶다는 말에 터미널로 책을 읽으면 되는거 아니냐는 이야기가 나와서, 설마 Neovim 플러그인 중에 epub 플러그인이 있을까? 하고 알아봤다. 진짜 있다. vim 사용자들의 집념은 뭘까 진짜...
@[email protected] · Reply to Woojin Kim's post
@me 흠.. 이름이 어감이 좀...
One of the new skills required to get the most out of AI-assisted coding tools - Claude Code, Codex CLI, etc - is designing agentic loops: carefully selecting tools to run in a loop to achieve a specified goal. Do this well and you can solve many coding problems with brute force
Here's my expanded explanation of what it means to design an agentic loop, how to do it safely (while running in YOLO mode!) and kinds of interesting problems this approach can be used to tackle https://simonwillison.net/2025/Sep/30/designing-agentic-loops/
룸싸롱 접대가 업무에 영향 있었는지 알 수 없다고? 어 그럼... 지귀연이 룸싸롱 간 것도 맞도 룸싸롱에서 술 마신 것도 맞고 룸싸롱에 결제한 건 남이 해준 것도 맞는 거야...? 그냥 그걸 받아먹고 청탁 들어줬는지는 알 수 없다 이거야...? 그럼 받아먹은 건 맞다는 거야...? 근데 그냥 놔둔다고? 룸싸롱 접대는 받았는데? 이 말인가? 룸싸롱 얘기 너무 많아서 룸싸롱탈트 붕괴 올 것 같음.
일단 룸싸롱 접대를 맞는 거 자체가 문제 아닌가? 접대 너무 많이 받아처먹어서 뇌가 이상해졌나? 그것도 룸싸롱 접대를?
@[email protected] · Reply to 염산하's post
@purengom 여하간 사람들이 카톡을 어떻게 쓰는지 카톡만 몰랐던 것인가... 싶고요
@[email protected] · Reply to 푸른곰's post
@purengom 카톡은 AI 때문이라기엔... ㅎㅎ
맥북 에어에서 제일 마음 드는 포트를 하나 꼽으라고 하면 3.5mm 헤드폰 포트 라고 대답할까봐요. 정말 괜찮네요.
@[email protected] · Reply to Woojin Kim's post
@me 사람이 어느 정도 간단히 상상할 수 있는 것들의 관계에서는 뉴턴 방식으로 생각하는 게 사실 더 직관적이긴 하죠 사과가 길을 따라가다니 뭔 소린가 싶고 ㅎㅎㅎ
궤도가 이동진의 파이아키아 채널에 나와서 인터스텔라 영화에 대해 이야기하는 영상을 봤다. 거기서
광자는 질량이 없는 것으로 여겨진다. 그런데 블랙홀은 빛도 탈출할 수 없는 곳이다. 뉴턴의 법칙에 따르면 광자가 질량이 없다면 중력과 상호작용하지 않을 것이다. 그래서 블랙홀이 있다고 해도 빛에 영향을 주지 않을 것이다. 중력이 시공간의 형태에 의해서 나타나는 현상이라고 해야 블랙홀로 빛이 끌려가는 현상이 설명 가능하다.
라는 취지로 설명하는 것을 들었는데, 이런 식의 설명은 처음 들어봤다. 오호...
@[email protected] · Reply to Woojin Kim's post
@me 저도 이번에 깜짝 놀랐지 뭡니까...
종립님이 인상적이라고 하신 리스크 테이커를 읽기 시작했다. 이 사람이 네이트 실버구나... #독서
@[email protected] · Reply to 염산하's post
공부는 스스로, 하고 싶은 것을 배우고 익히는 것. 지식보다 사고력. 대학교육 자체는 통계적으로 유의미한 사고력 증진을 끌어내지 못했다.
@[email protected] · Reply to 염산하's post
공부의 재발견. 최근의 학습과학의 성과를 알리고 교육이 아닌 “공부”에 집중하고자 함, 이라고 서문에서 이야기하는 책. 마인드스케일 좋아하는데 요 책도 그래서 좋았다. 흠? 혹시 이 교수님도 유튜브 하시려나?
@[email protected] · Reply to Woojin Kim's post
@me 저 그거 알아요 F1 피트 스탑!
@[email protected] · Reply to Woojin Kim's post
@me 둘 다를 골라야 합니다 저는.
아니 사람들이 이렇게나 카톡 프로필에 사진을 많이 올렸었나? 인스타랑 다를 바가 없었네...
@[email protected] · Reply to 염산하's post
연구 결과 학습 방법과 무관하게 질문을 목표로 삼은 집단이 더 많은 수의 좋은 질문을 만들어 냈습니다. 더 놀라운 점은 질문 집단이 이해 집단(내용 이해를 목표로 삼은 집단)보다 학습 내용을 더 잘 이해했다는 겁니다. 책을 읽거나 강의를 들을 때 질문하는 행위 자체에 초점을 두어 보세요. 그 과정에서 이해는 절로 따라올 겁니다.
@[email protected] · Reply to 염산하's post
글의 내용에 동의하는지, 글의 느낌은 어떤지, 글의 장점과 단점은 무엇인지 분석하는 것도 반성적 읽기의 일환입니다. 이를 통해 우리는 글을 다각적으로 이해하거나 겉으로는 드러나지 않던 새로운 의미를 찾아낼 수 있습니다. 반성적 읽기 능력은 배경지식을 많이 가지고 있다고 해서 저절로 늘지 않습니다. 글의 내용을 평가하고, 비판하고, 발전시키려는 의도적인 노력을 기울여야 조금씩 발전합니다.
오, 애플 워치 시리즈 5 배터리 성능 수준 68% 라서 리퍼 받았는데 시리즈 6로 업글돼서 왔다! 두 세대 전 OS 쓰고 있었는데 최신 oS 설치가 되네!
Disclaimer
이 글은 NestJS를 공부하면서 객체지향 프로그래밍 원칙과의 연결점을 스스로 정리한 내용입니다. Spring 같은 프레임워크를 이해할 때 객체지향 개념이 중요한 것처럼, NestJS 역시 객체지향 설계를 염두에 두면 훨씬 더 깊이 이해할 수 있을 것 같다는 관점에서 작성되었습니다.
소프트웨어는 시간이 지날수록 점점 복잡해지고, 원래 의도와 다르게 무너질 위험에 쉽게 노출됩니다. “한 클래스가 너무 많은 일을 한다”, “새로운 기능 하나 추가하려는데 기존 코드를 몽땅 뜯어고쳐야 한다”, “교체 가능한 구현체인데도 특정 코드에 딱 달라붙어버렸다”… 이런 상황을 겪어본 개발자는 많을 겁니다.
이러한 문제를 피하기 위해 정리된 다섯 가지 핵심 규칙이 바로 SOLID 원칙입니다. 이 개념은 소프트웨어 엔지니어 Robert C. Martin(일명 Uncle Bob) 이 다섯 가지 원칙을 하나의 묶음으로 제시하면서 널리 알려졌습니다. 이후로 사실상 “좋은 코드”를 판단하는 표준처럼 자리 잡았습니다.
하지만 SOLID는 객체지향 프로그래밍 전용 규칙이 아닙니다. 함수형 프로그래밍에도 적용할 수 있고, React 같은 UI 라이브러리, 오픈소스 프레임워크 내부 구조를 설계할 때도 그대로 통하는 일반적인 소프트웨어 설계 원칙 입니다. 이번 글에서는 NestJS를 예시로 삼아, 각 원칙이 어떤 문제를 해결하고 실제 코드에 어떻게 녹여낼 수 있는지 살펴보겠습니다.
SRP는 “한 클래스는 오직 하나의 책임만 가져야 한다” 는 원칙으로, 여러 기능이 한곳에 얽히면 서로 다른 이유로 동시에 수정되어야 하므로 유지보수가 어려워집니다. NestJS가 Controller, Service, Repository를 나누는 구조를 제공하는 것도 사실 이 원칙을 실현하기 위함입니다.
❌ 위반 사례
@Controller('users')
export class UserController {
constructor(private readonly repo: Repository<User>) {}
@Get(':id')
async getUser(@Param('id') id: string) {
const user = await this.repo.findOneBy({ id });
if (!user?.isActive) throw new Error('Inactive user');
return { id: user.id, name: user.name };
}
}✅ 개선 사례
@Controller('users')
export class UserController {
constructor(private readonly userService: UserService) {}
@Get(':id')
getUser(@Param('id') id: string) {
return this.userService.findOne(id);
}
}
@Injectable()
export class UserService {
constructor(private readonly repo: Repository<User>) {}
async findOne(id: string) {
const user = await this.repo.findOneBy({ id });
if (!user?.isActive) throw new Error('Inactive user');
return user;
}
}Controller는 요청과 응답만 담당하고, Service는 비즈니스 로직만 다루며, Repository는 데이터베이스 접근에만 집중하게 나누면 각 계층이 독립적으로 바뀔 수 있고 코드의 응집도와 유지보수성이 높아집니다.
📊 다이어그램
OCP는 “소프트웨어 개체는 확장에는 열려 있고, 변경에는 닫혀 있어야 한다” 는 원칙입니다. 즉, 새로운 기능을 넣더라도 기존 코드를 직접 수정하지 않고 확장 방식으로 처리할 수 있어야 한다는 뜻입니다.
❌ 위반 사례
@Injectable()
export class UserService {
async findOne(id: string) {
console.log(`[LOG] fetching user ${id}`);
return { id };
}
}✅ 개선 사례
@Injectable()
export class LoggingInterceptor implements NestInterceptor {
intercept(context: ExecutionContext, next: CallHandler) {
const req = context.switchToHttp().getRequest();
console.log(`[LOG] ${req.method} ${req.url}`);
return next.handle();
}
}
@Module({
providers: [{ provide: APP_INTERCEPTOR, useClass: LoggingInterceptor }],
})
export class AppModule {}UserService는 오직 사용자 로직만 담당하도록 두고, 로깅은 Interceptor로 분리하면 로깅 전략을 바꾸거나 새로운 로깅 방식을 추가할 때 기존 코드를 건드리지 않고 확장만으로 대응할 수 있습니다.
📊 다이어그램
LSP는 “상위 타입을 사용하는 코드는 하위 타입으로 교체하더라도 정상적으로 동작해야 한다” 는 원칙입니다. MIT의 Barbara Liskov 교수가 1987년 발표한 개념으로, 인터페이스를 구현한 객체라면 언제든 안정적으로 대체 가능해야 한다는 점을 강조합니다.
❌ 위반 사례
export class StripeGateway {
pay(amount: number): string {
return `Paid ${amount} via Stripe`;
}
}
export class TossGateway extends StripeGateway {
pay(amount: number): string {
throw new Error('Toss unavailable ❌');
}
}✅ 개선 사례
export interface PaymentGateway {
pay(amount: number): string;
}
export class StripeGateway implements PaymentGateway {
pay(amount: number) {
return `Paid ${amount} via Stripe`;
}
}
export class TossGateway implements PaymentGateway {
pay(amount: number) {
return `Paid ${amount} via Toss`;
}
}PaymentService는 인터페이스인 PaymentGateway에만 의존하고, 실제 구현체는 계약(pay 메서드)만 지키면 언제든 교체 가능하므로, 코드의 일관성과 신뢰성이 보장됩니다.
📊 다이어그램
ISP는 “클라이언트는 자신이 사용하지 않는 메서드에 의존하지 않아야 한다” 는 원칙으로, 거대한 인터페이스가 불필요한 의존을 강제하는 문제를 막고자 합니다. NestJS에서는 Guard, Pipe, Interceptor, Filter 등이 이 원칙을 잘 반영합니다.
❌ 위반 사례
class UglyRequestHandler {
handle(req: any): any {
try {
this.authenticate(req);
this.validate(req);
this.log(req);
const result = this.execute(req);
return { statusCode: 201, message: '회원가입 성공', data: result };
} catch (err: any) {
return this.catchError(err);
}
}
private authenticate(req: any) { /* ... */ }
private validate(req: any) { /* ... */ }
private log(req: any) { /* ... */ }
private execute(req: any) { /* ... */ }
private catchError(err: any) { /* ... */ }
}✅ 개선 사례
@Controller('auth')
@UseFilters(HttpExceptionFilter)
export class AuthController {
constructor(private readonly authService: AuthService) {}
@UseGuards(GuestOnlyGuard)
@UsePipes(new ValidationPipe())
@UseInterceptors(LoggingInterceptor)
@Post('signup')
async signup(@Body() dto: CreateUserDto) {
return this.authService.signup(dto);
}
}인증은 Guard, 검증은 Pipe, 로깅은 Interceptor, 에러 처리는 Filter가 담당하도록 분리하면 각 기능을 독립적으로 교체하거나 확장할 수 있고, 컨트롤러는 핵심 흐름만 관리할 수 있어 불필요한 의존이 사라집니다.
📊 다이어그램
DIP는 “고수준 모듈은 저수준 모듈에 의존하지 않고, 추상화에 의존해야 한다” 는 원칙입니다. 구체 구현체에 묶여버리면 교체가 어려워지고, 시스템 전체가 쉽게 깨지기 때문에 등장한 개념입니다.
❌ 위반 사례
@Injectable()
export class UserService {
async createUser(name: string) {
console.log('User created:', name);
}
}✅ 개선 사례
export interface LoggerPort {
log(message: string): void;
}
@Injectable()
export class ConsoleLogger implements LoggerPort {
log(message: string) {
console.log(message);
}
}
@Injectable()
export class UserService {
constructor(private readonly logger: LoggerPort) {}
async createUser(name: string) {
this.logger.log(`User created: ${name}`);
}
}
@Module({
providers: [{ provide: 'LOGGER', useClass: ConsoleLogger }],
})
export class AppModule {}UserService는 LoggerPort라는 추상화에만 의존하고, 실제 구현은 DI 컨테이너에서 주입되므로 언제든 다른 로거(ConsoleLogger, WinstonLogger, LogtapeLogger, FileLogger 등)로 교체할 수 있어 코드가 훨씬 유연해집니다.
📊 다이어그램
SOLID는 오래 살아남는 코드를 위한 다섯 가지 약속입니다. 책임을 분리해 응집도를 높이고(SRP), 기존 코드를 건드리지 않고 확장할 수 있도록 만들며(OCP), 계약을 지켜 일관성을 유지하고(LSP), 불필요한 의존을 줄이고(ISP), 추상화를 통해 교체 가능성을 확보합니다(DIP).
세부적인 구현은 둘째치더라도 NestJS는 Guard, Pipe, Interceptor, DI Container 등 이미 SOLID를 녹여낼 수 있는 구조적 도구들을 제공합니다. SOLID는 특정 프레임워크의 패턴이 아니라, 현대 소프트웨어 전반에 알게 모르게 스며들어 있는 보편적 원칙이라고 할 수 있습니다.
글을 읽으시다가 사실과 다른 부분이 보이거나 설명이 모호해 보이는 지점, 혹은 보완하면 더 나아질 것 같은 아이디어가 떠오르신다면, 사소한 것이라도 편하게 지적해 주세요—빠르게 반영하며 글과 코드를 함께 다듬어 보겠습니다.