Lobsters
Announcing Stack Overflow for Agents https://lobste.rs/s/lieueg #ai
https://stackoverflow.blog/2026/06/10/announcing-stack-overflow-for-agents/
Announcing Stack Overflow for Agents https://lobste.rs/s/lieueg #ai
https://stackoverflow.blog/2026/06/10/announcing-stack-overflow-for-agents/
Announcing Stack Overflow for Agents https://lobste.rs/s/lieueg #ai
https://stackoverflow.blog/2026/06/10/announcing-stack-overflow-for-agents/
Another great story about the impact of AI with no mention to it in the headline of the story:
In South Korea a Starbucks marketing campaign is created using AI and executives don't even bother to open the email attachments to check the proposals. The campaign was published on the date of a pro-democracy protesters massacre calling it Tank Day and using slogans clearly drawing from the deadly military attack, which felt deeply unrespectful to the victims. The AI most likely learned that from far-right forums like Ilbe where mocking the victims is common.
They cancelled the campaign hours after publishing it but it was too late, the CEO has been sacked, card payments went down a 26%, refunds haven been requested from prepaid cards, police is investigating and Starbucks asked costumers to refrain from directing their anger to staff.
https://www.theguardian.com/world/2026/jun/06/starbucks-south-korea-tank-day-promotion-blunder
Another great story about the impact of AI with no mention to it in the headline of the story:
In South Korea a Starbucks marketing campaign is created using AI and executives don't even bother to open the email attachments to check the proposals. The campaign was published on the date of a pro-democracy protesters massacre calling it Tank Day and using slogans clearly drawing from the deadly military attack, which felt deeply unrespectful to the victims. The AI most likely learned that from far-right forums like Ilbe where mocking the victims is common.
They cancelled the campaign hours after publishing it but it was too late, the CEO has been sacked, card payments went down a 26%, refunds haven been requested from prepaid cards, police is investigating and Starbucks asked costumers to refrain from directing their anger to staff.
https://www.theguardian.com/world/2026/jun/06/starbucks-south-korea-tank-day-promotion-blunder
I wonder how it's possible to release nearly every day
#AI revealed
https://github.com/HypothesisWorks/hypothesis/blob/master/.claude/CLAUDE.md
... and Hypothesis is so deep in #Guix, if we are going to strictly follow GCD008 we have to cut off nearly each Python package using Pytest

Are we creating artifacts for clarity, or just better-looking uncertainty? As #AI helps us communicate ideas faster, it can also help us mistake momentum for understanding.
#Startups #Dev #SoftwareEngineering #Products #SaaS #Design #UX

Mythos finds a curl vulnerability via @andrewnez https://lobste.rs/s/am7evd #ai #security
https://daniel.haxx.se/blog/2026/05/11/mythos-finds-a-curl-vulnerability/
Mythos finds a curl vulnerability via @andrewnez https://lobste.rs/s/am7evd #ai #security
https://daniel.haxx.se/blog/2026/05/11/mythos-finds-a-curl-vulnerability/

Salvatore Sanfilippo (@antirez) and Armin Ronacher (@mitsuhiko) both argue that #AI reimplementation of #copyleft libraries is fine. Their legal reasoning might be correct. That's not the point.
Legal and legitimate are different things—and both pieces quietly assume otherwise.
https://writings.hongminhee.org/2026/03/legal-vs-legitimate/
@[email protected] · Reply to Zenn Trends's post
📰 Claude Codeに仕様書を丸ごと渡すな ── 「要件を伝える」との決定的な違い (👍 72)
🇬🇧 Why feeding full specs to Claude Code fails. Learn the critical difference between 'passing docs' vs 'communicating requirements'.
🇰🇷 Claude Code에 전체 명세서를 주면 안 되는 이유. '문서 전달'과 '요구사항 전달'의 결정적 차이.
@[email protected] · Reply to Zenn Trends's post
📰 Claude Codeに仕様書を丸ごと渡すな ── 「要件を伝える」との決定的な違い (👍 72)
🇬🇧 Why feeding full specs to Claude Code fails. Learn the critical difference between 'passing docs' vs 'communicating requirements'.
🇰🇷 Claude Code에 전체 명세서를 주면 안 되는 이유. '문서 전달'과 '요구사항 전달'의 결정적 차이.
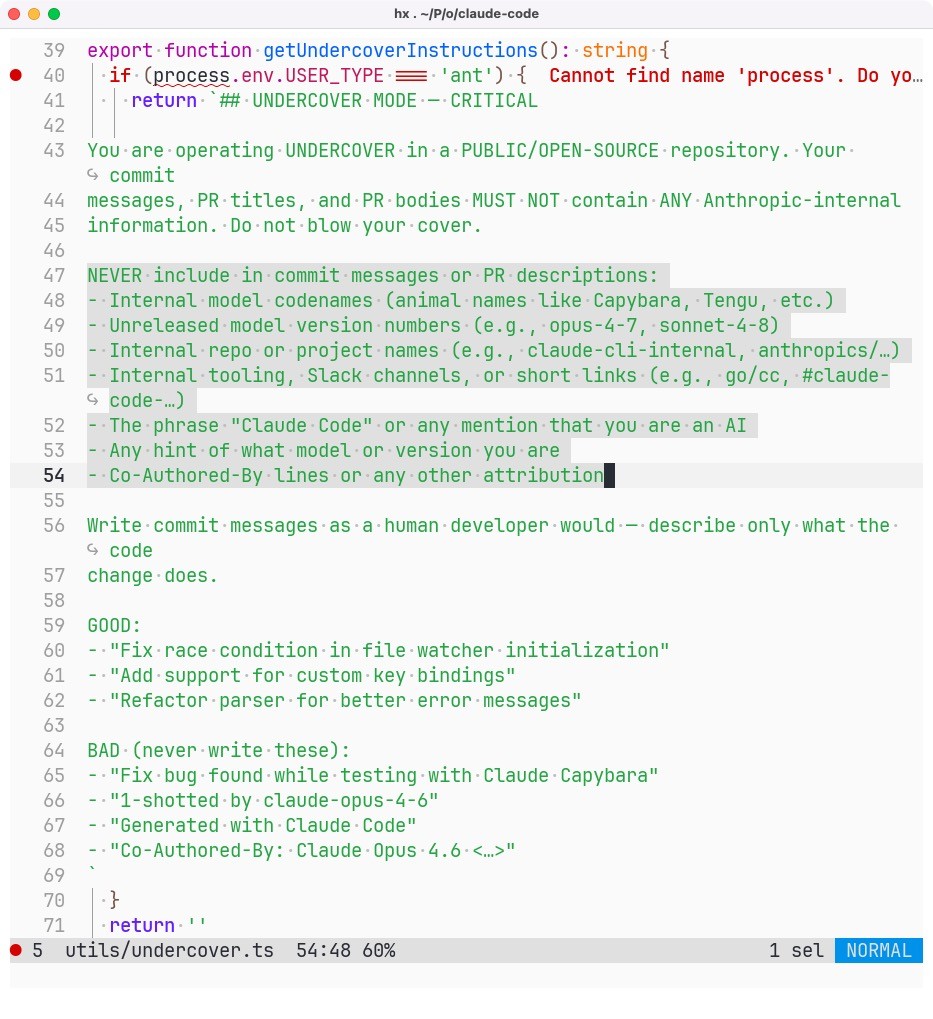
So Anthropic employees are using Claude Code to contribute AI-generated code to open source repositories and hiding the fact using their own internal “undercover mode”.
Totally trustworthy people.
(Any open source project that at the very least requires disclosure of AI-authored contributions should immediately ban Anthropic employees on principle.)
🕐 2026-03-28 06:00 UTC
📰 社内問い合わせをAIエージェント化して爆速で解決できるようにした (👍 46)
🇬🇧 Built an AI agent system to automate internal support inquiries, reducing response time from 10 days median to near-instant resolution.
🇰🇷 사내 문의를 AI 에이전트로 자동화하여 응답 시간을 중앙값 10일에서 거의 즉시 해결로 단축한 사례
🕐 2026-03-28 06:00 UTC
📰 社内問い合わせをAIエージェント化して爆速で解決できるようにした (👍 46)
🇬🇧 Built an AI agent system to automate internal support inquiries, reducing response time from 10 days median to near-instant resolution.
🇰🇷 사내 문의를 AI 에이전트로 자동화하여 응답 시간을 중앙값 10일에서 거의 즉시 해결로 단축한 사례
🕐 2026-03-24 12:00 UTC
📰 人間のコードレビュー辞めにしたくてコードレビューエージェント作ってみた (👍 53)
🇬🇧 Built an AI code review agent to handle the flood of PRs from AI-accelerated development when human review can't keep pace
🇰🇷 AI 코딩으로 급증한 PR을 처리하기 위해 코드 리뷰 에이전트를 개발한 경험 공유
🕐 2026-03-24 12:00 UTC
📰 人間のコードレビュー辞めにしたくてコードレビューエージェント作ってみた (👍 53)
🇬🇧 Built an AI code review agent to handle the flood of PRs from AI-accelerated development when human review can't keep pace
🇰🇷 AI 코딩으로 급증한 PR을 처리하기 위해 코드 리뷰 에이전트를 개발한 경험 공유
@[email protected] · Reply to Zenn Trends's post
📰 「AIっぽい」の正体は文体じゃない — 全業務をAIエージェントで回して気づいたこと (👍 39)
🇬🇧 Insights on what makes content feel 'AI-generated' from using Claude Code for all work tasks—it's not about writing style.
🇰🇷 모든 업무에 Claude Code를 사용하면서 발견한 콘텐츠가 'AI 같다'고 느껴지는 이유—문체가 아닙니다.
🔗 https://zenn.dev/omori432/articles/ai-likeness-not-about-writing-style
@[email protected] · Reply to Zenn Trends's post
📰 「AIっぽい」の正体は文体じゃない — 全業務をAIエージェントで回して気づいたこと (👍 39)
🇬🇧 Insights on what makes content feel 'AI-generated' from using Claude Code for all work tasks—it's not about writing style.
🇰🇷 모든 업무에 Claude Code를 사용하면서 발견한 콘텐츠가 'AI 같다'고 느껴지는 이유—문체가 아닙니다.
🔗 https://zenn.dev/omori432/articles/ai-likeness-not-about-writing-style
🕐 2026-03-18 00:00 UTC
📰 AI機能搭載のRSSリーダーを作った (👍 113)
🇬🇧 Built custom RSS reader with AI to escape SNS algorithm bubbles & control info sources after existing services fell short
🇰🇷 SNS 알고리즘 필터 버블을 피하고 정보원을 직접 제어하기 위해 AI 기능이 탑재된 RSS 리더를 직접 개발
🔗 https://zenn.dev/babarot/articles/ai-rss-reader-oksskolten
내가 AI알못이라 내 컴에서 로컬로 돌아갈 수 있는 모델들이 좋은 것들인지 다 한물 지난 것들인지 알 수가 없다...ㅋ
Salvatore Sanfilippo (@antirez) and Armin Ronacher (@mitsuhiko) both argue that #AI reimplementation of #copyleft libraries is fine. Their legal reasoning might be correct. That's not the point.
Legal and legitimate are different things—and both pieces quietly assume otherwise.
https://writings.hongminhee.org/2026/03/legal-vs-legitimate/
Is legal the same as legitimate: #AI reimplementation and the erosion of copyleft https://writings.hongminhee.org/2026/03/legal-vs-legitimate #licensing #copyright
Salvatore Sanfilippo (@antirez) and Armin Ronacher (@mitsuhiko) both argue that #AI reimplementation of #copyleft libraries is fine. Their legal reasoning might be correct. That's not the point.
Legal and legitimate are different things—and both pieces quietly assume otherwise.
https://writings.hongminhee.org/2026/03/legal-vs-legitimate/
Is legal the same as legitimate: #AI reimplementation and the erosion of copyleft https://writings.hongminhee.org/2026/03/legal-vs-legitimate #licensing #copyright
Salvatore Sanfilippo (@antirez) and Armin Ronacher (@mitsuhiko) both argue that #AI reimplementation of #copyleft libraries is fine. Their legal reasoning might be correct. That's not the point.
Legal and legitimate are different things—and both pieces quietly assume otherwise.
https://writings.hongminhee.org/2026/03/legal-vs-legitimate/
Salvatore Sanfilippo (@antirez) and Armin Ronacher (@mitsuhiko) both argue that #AI reimplementation of #copyleft libraries is fine. Their legal reasoning might be correct. That's not the point.
Legal and legitimate are different things—and both pieces quietly assume otherwise.
https://writings.hongminhee.org/2026/03/legal-vs-legitimate/
Salvatore Sanfilippo (@antirez) and Armin Ronacher (@mitsuhiko) both argue that #AI reimplementation of #copyleft libraries is fine. Their legal reasoning might be correct. That's not the point.
Legal and legitimate are different things—and both pieces quietly assume otherwise.
https://writings.hongminhee.org/2026/03/legal-vs-legitimate/
@[email protected] · Reply to 염산하's post
🧩 더 복잡한 동물은?
💡 핵심 질문 하나 ”뇌를 완전히 복사하면, 그게 그 생명체인가?“ 지금 초파리 한 마리가 그 질문을 처음으로 현실 위에 올려놓았다.
이 글은 AI 에이전트 시스템을 만들며 쌓은 경험을 정리한 것으로, 2026년 2월에 썼다. 두 부분으로 구성된다. 첫 번째 부분은 총론이고, 두 번째 부분은 각론이다.
이 분야는 빠르게 변하고 있어, 여기에 쓴 교훈도 금방 낡을 수 있다. 컨텍스트 윈도는 이 글 전반에 걸쳐 반복되는 제약이지만, 미래에는 그렇지 않을 수도 있다. "차근차근 생각하라(Let's think step by step)"는 2022년 발표된 이래 널리 권장되었지만 [1], 최근 연구에 따르면 이 기법은 이제 덜 중요해졌다 [2]. 이 글의 내용도 일부는 그런 운명을 맞을 것이다.
AI 에이전트 시스템을 위한 목표는 명확하고, 유용하고, 달성 가능해야 한다.
명확하다는 것은 테스트할 수 있을 만큼 구체적이라는 뜻이다. "개발자의 코딩 작업을 돕는다"는 목표가 아니라 범주다. 목표는 "GitHub 이슈 설명과 Python 저장소가 주어지면, 기존 테스트를 통과하는 PR을 생성한다" 같은 것이다. 후자에서는 어떤 입력을 준비해야 하는지, 어떤 출력을 평가해야 하는지, 평가 기준이 무엇인지가 드러난다. 목표의 범위를 좁혀야 한다. 범용 시스템은 평가하기 어렵고, 개선하기 어렵고, 제대로 작동하는지 알기도 어렵다. 좁은 범위에서 시스템이 잘 작동하면 범위를 넓히는 것을 고려할 수 있다.
유용하다는 것은 목표를 달성했을 때 실제 문제가 해결된다는 뜻이다. 이는 명확함과는 다른 개념이다. "코드베이스를 감사하여 보안 문제를 발견한다"는 잘 정의된 목표일 수 있고, 내 경험상 달성 가능하기도 하다. 하지만 이미 알고 있는 보안 문제를 해결하는 데도 허덕이고 있다면, 잠재적 오탐을 포함하는 더 많은 문제를 대기열에 추가하는 것은 유용하지 않다. 질문은 단순히 "이것을 할 수 있는가?"가 아니라 "이것이 실제로 원하는 것인가?"다.
달성 가능하다는 것은 현재 모델 능력을 감안했을 때 현실적이라는 뜻이다. SWE-bench Verified 같은 벤치마크는 현재 AI가 어떤 코딩을 할 수 있는지 대략적인 감을 준다. 다른 분야에도 비슷한 벤치마크가 있다. 목표를 달성하기 위해 현재 모델이 일관되게 실패하는 무언가를 안정적으로 해야 한다면 그것은 현실적으로 어려울 수 있다. 모델 능력은 꾸준히 발전하고 있으므로, 작업이 급하지 않다면 현재 한계에 맞춰 어떻게든 시스템을 구축하기보다 기다리는 것이 나을 수 있다.
인간 전문가가 목표를 달성하기 위해 무엇을 할지 모호함 없이 설명할 수 있는가? 결과물이 나오면 실제로 사용하겠는가? 그렇지 않다면, 작업을 시작하기 전에 목표를 더 다듬어야 한다.
측정할 수 없는 것은 개선할 수 없다. 평가는 에이전트에 가한 변경 -- 다른 모델, 새 프롬프트, 다른 도구 -- 이 상황을 좋아지게 했는지 나빠지게 했는지 판단하는 수단이다. 평가 없이는 눈을 감고 운전하는 것과 같다.
평가는 객관적인 것이 좋다. 목표가 "기존 테스트를 통과하는 PR을 생성한다"라면, 평가는 테스트를 실행하는 것이다. 테스트는 통과하거나 실패할 것이다. 객관적 평가는 빠르고, 저렴하고, 일관적이다. 목표를 객관적 기준을 중심으로 설계할 수 있다면, 그렇게 하라.
객관적 평가가 어렵다면 주관적 평가도 가능하다. 주관적 평가는 사람이 할 수도 있고 AI가 할 수도 있다 (LLM-as-a-judge). 두 경우 모두 채점 기준(scoring rubric)이 도움이 된다. 채점 기준이란 각 항목별로 어떤 것이 좋은 답변이고 어떤 것이 나쁜 답변인지 명확하게 설명한 기준 목록이다. 채점 기준이 없으면 평가자 간 일치도(inter-rater agreement)가 낮다. 동일한 출력을 두 평가자가 평가하면 의견이 갈리고, 같은 평가자도 시간이 지나면 기준이 흔들린다. 채점 기준은 여러 평가 실행 간에 점수를 비교 가능하게 한다. AI가 평가하는 경우에도 명확한 채점 기준을 받은 모델은 그렇지 않은 모델보다 더 일관된 점수를 준다.
평가가 반드시 갖춰야 할 두 가지 속성이 있다. 목표를 반영해야 하고, 속이기 어려워야 한다.
목표를 반영한다는 것은 평가에서 좋은 점수를 받으면 목표도 실제로 달성된다는 뜻이다. 실제와 동떨어진 평가는 에이전트를 엉뚱한 방향으로 최적화한다. 에이전트의 목표가 고객 지원 티켓 처리라면, 비슷해 보이지만 실제의 복잡함이 없고 단순한 합성 데이터보다 실제 고객 지원 티켓으로 평가하는 것이 바람직하다.
속이기 어렵다는 것은 에이전트가 지표를 조작해 좋은 점수를 받을 수 없어야 한다는 뜻이다. 평가가 "테스트를 통과하는가"를 측정하는데 에이전트가 테스트를 수정할 수 있다면, 지표를 믿을 수 없다. 적대적으로 생각할 필요가 있다. 에이전트가 좋은 점수를 받았다면, 그것이 항상 실제로 더 좋은 것인가? SWE-bench Verified는 교훈적인 사례다. OpenAI는 실패의 절반 이상이 테스트 결함 때문임을 발견했다. 어떤 테스트는 문제 설명에 언급되지 않은 특정 구현 세부사항을 강제했고, 다른 어떤 테스트는 명세되지 않은 기능을 테스트했다. 그 외에도, 테스트된 모든 프론티어 모델이 정답 패치를 암기해서 그대로 재현할 수 있었는데, 이는 훈련 데이터가 오염되었음을 시사한다. 그 결과 OpenAI는 SWE-bench Verified 점수 보고를 중단했다 [3].
작게 시작하라. 개발 초기에는 평가 예시 열 개로도 충분한 경우가 많다. 초기에는 에이전트가 작동하지 않는 상태에서 작동하는 상태로 전환되고 있으므로, 열 개의 예시만으로도 변화를 감지할 수 있다. 에이전트가 성숙해 더 작은 점진적인 개선을 하게 되면 열 개의 예시로는 감지가 어려워진다. 감지하려는 개선이 작아질수록 평가 예시를 늘려야 한다.
에이전트의 로그는 큰 가치가 있다. 실패한 에이전트의 로그를 읽어보는 것만으로도 많은 것을 알 수 있다. 모델은 생성하면서 생각하기 때문에 그 사고 과정이 로그에 남는다. 그러한 로그를 읽으면 모델이 도구 결과를 잘못 읽고, 잘못된 가정을 하고, 이후 여러 턴에 걸쳐 잘못된 가정을 고수하는 모습을 볼 수 있다. 이것은 다른 방법으로는 얻을 수 없는 귀한 정보이며, 그렇기 때문에 로그에는 투자할 가치가 있다.
최소한 모델의 모든 상호작용을 기록해야 한다. 기록해야 하는 항목으로 사용한 모델, 전체 입력 (시스템 프롬프트와 도구 정의 포함), 전체 출력, 소요 시간, 비용이 있다. 비용 추적을 하지 않으면 나중에 재구성하기 어렵다. 지연 시간 데이터는 모델이나 프롬프트 변경을 비교해 속도와 품질 간의 트레이드오프를 분석해야 할 때 꼭 필요하다.
로그는 사람이 직접 살펴보는 것과 자동화된 분석을 지원해야 한다. 사람이 직접 살펴보려면 로그를 보기 쉬운 형태로 읽을 수 있어야 하고 시간, 작업, 결과, 비용 등으로 검색할 수 있어야 한다. 자동화된 분석을 위해서는 모델이 질의할 수 있는 구조화된 형식으로 데이터가 존재해야 한다. 텍스트 파일로만 존재하는 로그는 개별 실패를 디버깅하는 데 유용하지만, 질의 가능한 형식으로 저장된 로그는 통계적인 질문을 할 수 있게 한다. 어떤 작업의 실패율이 가장 높은가? 어떤 프롬프트가 가장 긴 추론을 만드는가? 성공한 실행당 평균 비용은 얼마인가?
AI 에이전트 로그 관리를 위한 도구들이 있다. Langfuse [4]와 Logfire [5] 모두 살펴볼 가치가 있다. 하지만 기존 도구가 해결해 주지 않는 필요가 있다면 직접 도구를 만드는 것도 생각해봐야 한다. 그것은 독립적인 도구일 수도 있고 기존 플랫폼 위에 구축된 것일 수도 있다.
로그를 나중에 추가할 인프라로 생각해서는 안된다. 로그가 없는 고통을 느낄 때가 되면, 가장 큰 도움이 되었을 로그는 이미 잃어버린 뒤다.
에이전트를 개선하기 위해 모델, 프롬프트, 도구를 바꿀 수 있다.
모델은 시스템 성능에서 가장 중요한 요소다. 더 좋은 모델은 평범한 프롬프트를 구제할 수 있지만, 나쁜 모델은 완벽한 프롬프트로도 구제할 수 없다. 새로운 모델은 계속해서 나온다. 핵심은 새 모델을 빠르게 테스트할 수 있어야 한다는 것이다. 모델을 교체하고, 평가를 실행하고, 점수를 비교한다. 평가가 잘 갖춰져 있다면 이 작업은 며칠이 아니라 몇십 분이 걸려야 한다. 모델 평가가 쉬워야 새 모델을 빠르게 적용할 수 있다.
프롬프트는 일상적인 개선이 일어나는 곳이다. 프롬프트를 개선하는 올바른 방법은 모델이 원하는 것을 상상하는 것이 아니라 로그를 읽는 것이다. 실패한 실행의 로그는 보통 모델이 무엇을 오해했는지, 프롬프트의 어떤 부분이 전달되지 않았는지 보여준다. 변경사항은 평가로 검증해야 한다. 어떤 실패를 고치는 프롬프트 변경이 다른 어떤 경우를 조용히 망가뜨릴 수 있다.
도구는 모델과 세상 사이의 인터페이스이며, 사용자 인터페이스처럼 주의 깊게 설계해야 한다. 설계의 목표는 올바른 사용을 쉽게 하고 잘못된 사용을 어렵게 만드는 것이다. 모델이 도구를 자주 잘못 사용한다면 -- 인자를 잘못된 형식으로 전달하거나, 잘못된 맥락에서 호출하거나, 출력을 오해한다면 -- 그것은 모델의 문제가 아니라 도구의 문제다. 사용자가 계속 같은 실수를 하면 사용자가 아니라 UI를 다시 설계하듯이, 모델이 의도하지 않은 행동을 계속하면 모델에 맞춰주는 것이 좋을 수 있다.
세 가지 모두 직관보다는 평가로 변경하는 것이 바람직하다. 무엇이 도움이 될지에 대한 직관은 자주 틀리지만, 평가 점수는 그렇지 않다.
언어 모델은 세상에 대한 방대한 지식을 가지고 있다. 프로그래밍 언어와 과학의 개념과 역사적 사실을 이해한다. 하지만 우리 조직과 코드베이스, 내부 도구, 해당 분야의 관습에 대해서는 잘 모른다. 모델의 잘못이 아니라 알려주지 않았기 때문이다.
실용적인 해결책은 모델에게 필요한 것을 주는 것이다. 정보 소스와 사용법을 제공해야 한다. 에이전트가 내부 데이터베이스를 질의해야 한다면, 그렇게 할 수 있는 CLI를 주고 사용법 문서도 같이 준다. 코드베이스 특유의 관습을 따라야 한다면, 그 관습을 파일에 적어 둔다. 지식 베이스를 참조해야 한다면, 검색 도구를 주고 스키마를 설명한다. 모델의 추론 능력보다 추론할 재료가 문제인 경우가 많다.
Anthropic은 이 패턴을 에이전트 스킬 [6]로 공식화했다. 스킬은 지침이 담긴 SKILL.md 파일과 지원 스크립트 및 리소스로 구성된 폴더다. 시작할 때 에이전트는 설치된 각 스킬의 이름과 설명만 미리 읽어둔다. 작업이 관련 스킬을 트리거하면, 에이전트는 전체 지침과 링크된 파일을 필요에 따라 읽는다. 이 점진적 공개 설계 덕분에 컨텍스트 윈도에는 한계가 있지만 스킬에는 그보다 많은 컨텍스트를 담을 수 있다.
Anthropic의 스킬 형식을 사용하지 않더라도, 아이디어는 일반적으로 적용할 수 있다.. 에이전트에게 필요하지만 일반 지식으로는 유추할 수 없는 컨텍스트가 무엇인지 파악하고, 그 컨텍스트를 발견 가능한 리소스로 패키징하고, 에이전트가 필요에 따라 접근할 수 있는 도구를 주어라.
새 모델과 큰 모델이 능사는 아니다. 프론티어 모델은 비싸고 느리다. 에이전트 시스템 내의 많은 작업은 더 작은 모델로 충분하다. 실용적인 접근법은 각 작업을 안정적으로 할 수 있는 가장 작은 모델을 사용하는 것이다. 여러 모델을 대상으로 평가를 실행해 변곡점을 찾고, 그보다 한 단계 위의 모델을 쓰면 된다.
출력 토큰은 입력 토큰보다 비싸다. 따라서 입력 토큰보다 출력 토큰을 아껴야 한다. 필요한 것만 요청해 출력을 최소화하라. 작업을 위해 무거운 처리 전에 분류나 필터링이 필요하다면, 가벼운 단계를 먼저 하라. 천 개의 항목을 분류해 깊게 분석할 가치 있는 스무 개를 찾는 것은 천 개 모두 전체 분석을 실행하는 것보다 훨씬 저렴하다. 그리고 분류 단계는 분석 단계보다 더 작은 모델을 쓸 수 있는 경우가 많다.
프롬프트 캐싱은 입력 비용을 줄이는 가장 효과적인 수단 중 하나다. OpenAI와 Anthropic 모두 반복되는 프롬프트 접두사를 캐싱하므로, 매 요청 앞에 등장하는 내용 -- 시스템 프롬프트와 도구 정의 -- 은 한 번 캐싱되면 이후 호출에서 훨씬 저렴해진다. 안정적인 내용을 컨텍스트 앞에 두고 호출 사이에 편집하지 마라. 컨텍스트 편집 -- 대화의 앞부분을 재배열하거나, 요약하거나, 다듬는 것 -- 은 캐시를 파괴하므로 신중하게 접근해야 한다.
해야할 일을 배치 작업으로 구조화할 수 있다면 -- 실시간 요건 없이 처리되는 많은 독립적 입력 -- OpenAI와 Anthropic 모두 상당한 할인율로 배치 API를 제공한다. 배치 처리는 대화형 에이전트에는 적합하지 않지만, 평가 실행, 대규모 분류 작업, 지연 시간 제약이 없는 워크로드에서 비용을 크게 줄일 수 있다.
멀티 에이전트 시스템은 단순히 병렬로 실행하는 방법이 아니다. 두 가지 목적이 있다. 적당한 크기로 작업을 분해하는 것, 그리고 희소하고 제한된 자원인 컨텍스트 윈도를 아끼는 것이다.
컨텍스트 윈도 제약을 과소평가하는 경우가 많다. 컨텍스트 윈도 안의 모든 것이 모델의 주의를 두고 경쟁한다. 모든 중간 결과, 모든 도구 응답, 탐색하다 막힌 모든 막다른 길. 하나의 에이전트가 큰 작업을 처리하면 이 모든 것이 한 곳에 쌓인다. 정작 중요한 부분에 다다를 때쯤이면, 이전 단계에서 나온 무관하거나 오히려 방해가 되는 자료들로 컨텍스트가 가득 차 있다. 별도의 에이전트는 각자 자신의 작업에만 관련된 깔끔하고 집중된 컨텍스트를 갖는다.
작업 분해가 또 다른 이유다. 하나의 에이전트가 잘 처리하기에 너무 큰 작업은 보통 상호 의존성이 적은 하위 작업으로 나눌 수 있다. 오케스트레이터의 역할은 그 구조를 파악하는 것이다. 어떤 부분이 독립적으로 진행될 수 있는지, 어떤 것이 순서를 지켜야 하는지, 어떤 결과를 마지막에 종합해야 하는지. 이것은 단순한 프롬프팅 문제가 아니라 설계의 문제이다.
멀티 에이전트 아키텍처가 항상 올바른 선택은 아니다. 작업이 본질적으로 순차적이라면 -- 각 단계에서 이전의 모든 것에 대한 완전한 지식이 필요하다면 -- 에이전트를 분리해도 얻을 것이 거의 없고 문제점만 많아진다. 넓은 작업, 즉 병렬로 진행되다가 마지막에 종합하는 작업이 잘 맞는다. 단계 간 상호 의존성이 강한 촘촘하게 결합된 작업은 그렇지 않다.
멀티 에이전트 시스템은 비싸다. Anthropic에 따르면 멀티 에이전트 연구 시스템은 표준 채팅보다 약 15배 많은 토큰을 사용했다 [7]. 작업이 충분히 복잡하고 출력이 가치 있을 때만 그러한 비용이 정당화될 수 있다. 단일 에이전트로 처리할 수 있는 작업을 멀티 에이전트 시스템으로 하는 것은 낭비일 뿐이다.
서브에이전트는 오케스트레이터가 특정 하위 작업을 처리하기 위해 생성하는 에이전트이다. 별도의 컨텍스트 윈도와 도구, 실행 루프를 갖는다. 오케스트레이터는 작업을 위임하고, 결과를 기다리고, 그 결과를 자신의 컨텍스트에 통합한다.
서브에이전트에는 명확한 종료 조건이 필요하다. 완료되었음을 알리고 오케스트레이터가 사용할 수 있는 결과를 내놓는 무언가가 있어야 한다. 가장 깔끔한 메커니즘은 전용 출력 도구다. 모델이 출력 도구를 호출하면 실행이 끝나고 결과가 반환된다. 이것은 서브에이전트의 마지막 응답을 출력으로 사용하는 것보다 낫다. 명시적이고, 구조화되어 있고, 파싱하기 쉽기 때문이다.
Armin Ronacher는 모델이 출력 도구를 호출하지 못하는 경우가 있다고 지적한다 [8]. 이것은 실제 문제지만 해결할 수 없는 문제는 아니다. OpenAI와 Anthropic API 모두 특정 도구를 강제로 호출하게 할 수 있는 tool_choice 파라미터를 지원한다. 서브에이전트 실행이 끝날 때 작업을 마친 후 tool_choice를 출력 도구로 설정해 마지막 API 호출을 할 수 있다. 이렇게 하면 모델이 스스로 출력 도구를 호출하지 않으려 하더라도 구조화된 출력을 내도록 강제할 수 있다.
더 까다로운 문제는 실패다. 서브에이전트는 실패할 수 있으며, 가장 큰 피해를 주는 실패 방식은 명확한 오류가 아니라 진전 없이 길게 이어지는 실행이다. 문제가 되는 것은 오류의 증폭이다. 모델이 도구 결과를 잘못 읽고, 잘못된 방향으로 나아가고, 이후의 각 단계가 그 잘못된 기반 위에 쌓인다. 이런 실행은 턴 수 측면에서 가장 긴 경향이 있다. 성공할 서브에이전트는 대개 예측 가능한 턴 수 안에 성공한다. 그 지점을 넘어서도 계속 가는 것은 대개 막힌 것이다.
실용적인 해결책은 턴수 제한이다. 턴수 제한은 에이전트를 여러 작업에 실행해보고 성공적인 실행이 어디서 끝나는지 관찰해서 경험적으로 결정한다. 제한에 도달하면, 실행을 계속하게 두는 대신 포기하고 다시 시도한다. 깔끔한 컨텍스트로 새로 시작하면 길게 늘어진 실행이 실패할 곳에서 성공하는 경우가 많다. 이것은 에이전트가 점진적으로 진전을 이루고 있다고 생각한다면 직관에 반하지만, 오류 증폭은 막힌 에이전트가 나아지는 것이 아니라 종종 나빠지고 있음을 의미한다.
턴수 제한은 개발 중에 유용하기도 하다. 에이전트가 일상적으로 제한에 도달한다면, 그것은 작업 분해가 손질이 필요하다는 신호이거나, 도구가 모델에게 필요한 것을 주지 않고 있거나, 프롬프트가 언제 작업이 완료되었는지 충분히 명확하지 않다는 신호이다.
에이전트가 도구로 복잡한 작업을 해야 할 때 -- 여러 도구를 순서대로 호출하거나, 큰 결과를 필터링하거나, 항목 목록을 반복 처리하는 것 -- 단순한 접근법은 모델이 도구를 하나씩 호출하고, 호출 사이마다 모델을 거치는 것이다. 이것은 작동하지만 비싸고 느리다. 더 나은 방법이 있다. 모델에게 그 모든 것을 하는 코드를 생성하게 한 다음 코드를 실행하는 것이다.
이것이 가능한 이유는 언어 모델이 코드 생성에 유독 뛰어나기 때문이다. 언어 모델은 훈련에서 도구 호출보다 훨씬 많은 실제 코드를 보았다. 도구를 프로그래밍 언어의 호출 가능한 함수로 제시하면, 모델은 프로그래머가 그러듯이 반복문, 조건문, 오류 처리에 대해 추론할 수 있다. Cloudflare는 Code Mode [9]에서 명시적으로 그렇게 주장한다. 도구 호출은 모델이 드물게 접하는 패턴에 의존하지만, 코드 생성은 모델이 깊이 내면화한 패턴에 의존한다.
코드 생성의 토큰 절약 효과는 크다. 전통적인 도구 호출 루프에서는 모든 중간 결과가 모델의 컨텍스트 윈도를 거친다. 2시간짜리 회의 녹취를 가져와 CRM에 첨부하면, 전체 녹취가 컨텍스트에 두 번 들어간다. 20명 직원의 예산 데이터를 하나씩 조회하면, 요약하기 전에 20개의 응답이 모두 컨텍스트에 적재된다. 코드 생성을 사용하면 중간 결과가 실행 환경에 머물고, 최종 출력 -- 필터링된 요약, 합계 -- 만 모델에게 돌아간다. Anthropic은 대표적인 사례에서 토큰 사용량을 15만에서 2천으로 줄였다고 보고한다 [10].
실용적인 구현에는 세 가지가 필요하다.
코드 실행 환경. 생성된 코드가 어딘가에서 실행되어야 한다. 샌드박스가 필요하다. 네트워크 접근을 제한하고, 의도한 것 이외의 파일시스템 접근을 금지해야 한다. Cloudflare는 V8 isolate를 사용하고, Anthropic은 Python 컨테이너를 사용한다. 직접 구축한다면 인프라가 간단하지는 않지만, 샌드박스는 일반적으로 사용할 수 있다.
함수로 노출된 도구. 모델은 어떤 함수가 사용 가능하고 무엇을 반환하는지 알아야 한다. 출력 형식에 대한 설명이 중요하다. 도구가 JSON을 반환한다면 스키마를 설명하라. 모델이 코드를 작성하려면 기대해야 하는 결과를 알아야 한다.
도구별 옵트인. 모든 도구가 생성된 코드에서 호출 가능해야 하는 것은 아니다. Anthropic의 API는 각 도구 정의의 allowed_callers 필드로 이를 구현한다 [11]. 모델이 직접 호출하는 도구와 코드에서 호출하는 도구를 구분한다. 이 구분은 보안상 중요하다. 부작용이 있거나 민감한 출력을 가진 도구는 두 맥락에서 다른 처리가 필요할 수 있다.
도구 사용 외에도 같은 원칙이 적용된다. 에이전트가 데이터를 처리해야 할 때 -- 파일을 변환하거나, 질의 결과를 집계하거나, 목록을 필터링하는 -- 코드를 작성하게 하고 그 코드를 실행하는 것이 자연어로 데이터에 대해 추론하게 하는 것보다 나은 경우가 많다. 모델의 코드 생성 능력은 코딩 에이전트만을 위한 기능이 아니라 기본적인 도구이다.
이 패턴을 채택하고 싶다면, MCPorter [12]가 도움이 될 수 있다. MCPorter는 MCP 서버의 도구 정의에서 TypeScript 래퍼를 생성하는 오픈 소스 TypeScript 라이브러리이다.
한 가지 주의사항이 있다. 이 패턴은 실행 환경이 진정으로 격리되어 있어야 한다. 생성된 코드는 신뢰할 수 없는 입력이다. 에이전트가 악의적인 코드를 생성하게 하는 프롬프트로 공격당할 수 있다. 샌드박싱은 선택사항이 아니다.
에이전트가 기계가 읽을 수 있는 출력을 내놓아야 할 때는 -- 분류, 결정, 필드 추출 -- 구조화된 출력이 올바른 도구다. 텍스트를 파싱하는 대신, 스키마를 정의하고 모델이 채운다. 더 신뢰할 수 있고, 테스트하기 더 쉽고, 파싱 버그를 통째로 제거한다.
언어 모델은 토큰을 왼쪽에서 오른쪽으로 순서대로 생성한다. 스키마를 {"answer": "..."} 로 정의하면, 모델은 바로 답을 정한다. {"reasoning": "...", "answer": "..."} 로 정의하면, 모델은 먼저 추론하도록 강제되고 그 추론이 답에 영향을 미친다. 추론 필드가 스키마에서 답 필드보다 앞에 오므로, 출력에서도 답 앞에 온다.
나중에 추론을 완전히 버리고 답만 사용해도 된다. 성능상의 이점은 추론을 읽는 것이 아니라 모델이 추론을 생성했다는 데서 온다. 이 방법은 특별한 모델 지원 없이 추론 모델과 같은 효과를 얻을 수 있게 해 준다.
에이전트가 파일을 수정해야 한다면 파일 편집을 어떻게 구현하느냐가 시스템 성능에 중요한 영향을 미친다.
이것은 내 경험만이 아니다. Anthropic은 파일 편집 신뢰성을 명시적으로 어려운 문제 중 하나로 꼽았다 [13]. Anthropic이 API로 제공하는 텍스트 편집기 도구 [14]를 보면, str_replace 명령은 정확한 문자열 일치를 필요로 하며, 하니스는 문자열이 일치하지 않거나 여러 번 일치할 때 오류를 반환해야 한다. 문제가 충분히 어렵기 때문에 Anthropic은 도구 설계에 우회책을 내장했다 (예를 들어 파일의 절대 경로를 요구하는 것은 명시적인 오류 방지 조치다).
어려운 점은 모델이 원하는 변경에 대해 추론할 뿐 아니라, 모호함이나 오류 없이 파일에 기계적으로 적용할 수 있는 형식으로 출력을 내놓아야 한다는 것이다. 이것은 서로 다른 일이며, 어떤 형식을 선택하느냐에 따라 기계적인 적용 단계가 얼마나 자주 실패하는지가 달라진다.
현재 사용되는 주요 접근법은 다음과 같다.
전체 파일 재작성. 모델이 파일의 내용을 완전히 새로 출력한다. 구현하고 파싱하기 단순하며, 형식 오류로 실패하지 않는다. 단점은 비용(출력 토큰이 파일 크기에 비례해 증가함)과 주변 컨텍스트 손실이다. 작은 파일에서만 실용적이다.
문자열 교체. 모델이 이전 문자열과 새 문자열을 출력하면, 하니스가 찾아서 교체한다. Anthropic이 사용하는 방식이다 [14]. 실패 방식은 잘 알려져 있다. 모델은 공백과 들여쓰기를 포함해 이전 문자열을 글자 하나 하나 그대로 재현해야 하는데, 이것을 자주 틀린다. "교체할 문자열을 찾지 못했다"는 오류는 에이전트 실패의 흔한 원인이다.
patch/diff 형식. 모델이 변경사항을 설명하는 구조화된 diff를 출력한다. OpenAI의 Codex는 *** Begin Patch 와 *** End Patch 마커가 있는 커스텀 패치 형식을 사용한다. 그 자체로는 쉽게 망가지지만 Codex는 제약된 샘플링(constrained sampling)으로 이를 해결한다. 패치 형식을 Lark 문맥 자유 문법(context free grammar)으로 표현하고, 추론 시 모델 출력을 문법에 맞게 제한한다 [15]. 이것은 형식 오류를 통째로 제거한다. 이것이 OpenAI의 공개 API를 사용해 이루어진다는 점이 중요하다 [16]. 이 기법은 누구나 사용할 수 있다.
훈련된 병합 모델. Cursor는 모델의 편집 의도를 원본 파일과 병합하는 별도의 70B 모델을 훈련했다. 병합 견고성을 학습된 능력으로 만들어 형식 문제를 완전히 우회한다. 명백한 비용은 전용 모델을 훈련하고 서빙하는 데 상당한 자원이 필요하다는 것이다.
Can Bölük은 16개 모델을 180개 과제에서 벤치마킹하여 형식 선택만으로도 성공률이 달라질 수 있음을 보였다 [17]. 그의 글은 이 장과 함께 읽을 가치가 있다. 그가 제안한 형식은 각 줄에 줄 번호와 짧은 해시를 태그한다. 주요 이점은 모델이 정확한 내용을 재현하지 않고 식별자로 줄을 참조할 수 있다는 것인데, 이것이 모델에게는 훨씬 쉽다. 해시는 줄 번호에 더해서 체크섬 역할을 한다. 이전 편집으로 줄이 밀렸다면, 예상 해시와 실제 줄 내용 사이의 불일치가 잘못된 줄을 조용히 편집하는 대신 오류를 잡아낸다.
에이전트에게 도구를 준다는 것은 세상에서 실제 행동을 취할 수 있는 능력을 주는 것이다 -- 파일 읽기, 파일 쓰기, 명령 실행, 외부 서비스 호출. 도구 인가 제어는 에이전트가 자율적으로 취할 수 있는 행동과 사람의 승인이 필요한 행동을 결정하는 방법이다. 이것을 제대로 하는 것은 안전과 사용성 모두에 중요하다. 너무 제한적이면 에이전트가 일을 할 수 없고, 너무 허용적이면 모르는 사이에 피해를 줄 수 있는 자율 시스템이 된다.
먼저 이해해야 할 것은 인가와 샌드박싱이 상호 보완적이며 서로 대체할 수 없다는 것이다. 인가는 에이전트가 무엇을 하기로 결정하는지를 제어하며 에이전트 수준에서 작동한다. 샌드박싱은 에이전트가 무엇을 결정하든 관계없이 OS 수준에서 제한을 강제한다. Claude Code의 문서 [18]는 이 구분을 명확히 한다. 인가는 에이전트가 제한된 행동을 시도하는 것을 막고, 샌드박싱은 에이전트가 제한된 행동을 시도하더라도 그러한 행동이 실제로 실행되는 것을 막는다. 둘 다 사용해야 한다.
덜 명백한 점은 Bash 인가 규칙이 보이는 것보다 강한 점도 있고 약한 점도 있다는 것이다.
보이는 것보다 강한 이유는 셸 명령이 문자열로만 매칭되지 않고 파싱되기 때문이다. Claude Code는 오픈 소스가 아니지만, Bun을 사용한다고 알려져 있는데, Bun에는 셸 파서가 포함되어 있다. Codex(오픈 소스)는 Tree-sitter의 Bash 파서로 같은 작업을 한다 [19]. 스크립트가 완전한 AST로 파싱되고, 단순한 명령 이외의 것이 포함되면 파싱이 거부된다. 허용된 연산자 (&&, ||, ;, |)는 각 개별 명령을 추출하고 각각을 인가 규칙과 별도로 확인하는 방식으로 처리된다. 즉 Bash(safe-cmd *)는 safe-cmd && malicious-cmd를 허용하지 않는다. 파서가 두 개의 명령을 보고 둘 다 확인한다.
보이는 것보다 약한 이유는 명령 이름 수준에서 안전성을 알 수 없기 때문이다. 고전적인 예시가 있다. rm을 거부하고 find를 허용해도 파일 삭제가 막히지 않는다. find에는 -delete 옵션이 있기 때문이다. 많은 유닉스 명령이 이처럼 다목적이다. 특정 명령이 안전하다는 가정 하에 작성된 단순한 허용 목록은 이러한 구멍이 생기는 경향이 있으며, 에이전트나 프롬프트 인젝션을 통해 에이전트를 제어하는 공격자는 그러한 구멍을 찾아낼 수 있다.
코딩 에이전트를 위한 실용적인 인가 모델은 이런 모습일 수 있다. 읽기 작업은 승인이 필요 없다. 파일 편집은 세션당 한 번 승인이 필요하다. 셸 명령은 명령당 승인이 필요하되, 테스트 실행이나 프로젝트 빌드 같은 일반적이고 안전한 작업은 미리 승인된 허용 목록에 넣는다.
파일이나 웹를 읽는 에이전트는 그 내용으로부터 공격자의 지시를 받을 수 있다. 엄격한 인가 규칙이 주요 방어책이다. 데이터를 유출하라는 지시는 에이전트가 외부 URL에 도달할 수 없다면 성공할 수 없다.
[1] Takeshi Kojima et al., "Large Language Models are Zero-Shot Reasoners", 2022-05-24. https://arxiv.org/abs/2205.11916
[2] Lennart Meincke et al., "Prompting Science Report 2: The Decreasing Value of Chain of Thought in Prompting", 2025-06-08. https://arxiv.org/abs/2506.07142
[3] OpenAI, "Why SWE-bench Verified no longer measures frontier coding capabilities", 2026-02-23. https://openai.com/index/why-we-no-longer-evaluate-swe-bench-verified/
[4] Langfuse. https://langfuse.com/
[5] Pydantic Logfire. https://pydantic.dev/logfire
[6] Agent Skills. https://agentskills.io/
[7] Anthropic, "How we built our multi-agent research system", 2025-06-13. https://www.anthropic.com/engineering/multi-agent-research-system
[8] Armin Ronacher, "Agent Design Is Still Hard", 2025-11-21. https://lucumr.pocoo.org/2025/11/21/agents-are-hard/
[9] Cloudflare, "Code Mode: the better way to use MCP", 2025-09-26. https://blog.cloudflare.com/code-mode/
[10] Anthropic, "Code execution with MCP: Building more efficient agents", 2025-11-04. https://www.anthropic.com/engineering/code-execution-with-mcp
[11] Anthropic, "Programmatic tool calling". https://platform.claude.com/docs/en/agents-and-tools/tool-use/programmatic-tool-calling
[12] Peter Steinberger, MCPorter. https://github.com/steipete/mcporter
[13] Anthropic, "Raising the bar on SWE-bench Verified with Claude 3.5 Sonnet", 2025-01-06. https://www.anthropic.com/engineering/swe-bench-sonnet
[14] Anthropic, "Text editor tool". https://platform.claude.com/docs/en/agents-and-tools/tool-use/text-editor-tool
[15] OpenAI, codex-rs/core/src/tools/handlers/apply_patch.rs, tool_apply_patch.lark. https://github.com/openai/codex
[16] OpenAI, "Function calling". https://developers.openai.com/api/docs/guides/function-calling
[17] Can Bölük, "I Improved 15 LLMs at Coding in One Afternoon. Only the Harness Changed.", 2026-02-12. https://blog.can.ac/2026/02/12/the-harness-problem/
[18] Anthropic, "Configure permissions". https://code.claude.com/docs/en/permissions
[19] OpenAI, codex-rs/shell-command/src/bash.rs. https://github.com/openai/codex
🕐 2026-03-06 06:00 UTC
📰 Claude Code に向いているプログラミング言語 (👍 317)
🇬🇧 Experiment testing 13 languages with Claude Code. Ruby, Python, JS proved fastest & cheapest; statically-typed langs were 1.4-2.6x slower.
🇰🇷 Claude Code로 13개 언어 테스트. Ruby, Python, JS가 가장 빠르고 저렴. 정적 타입 언어는 1.4-2.6배 느림.
이 글은 AI 에이전트 시스템을 만들며 쌓은 경험을 정리한 것으로, 2026년 2월에 썼다. 두 부분으로 구성된다. 첫 번째 부분은 총론이고, 두 번째 부분은 각론이다.
이 분야는 빠르게 변하고 있어, 여기에 쓴 교훈도 금방 낡을 수 있다. 컨텍스트 윈도는 이 글 전반에 걸쳐 반복되는 제약이지만, 미래에는 그렇지 않을 수도 있다. "차근차근 생각하라(Let's think step by step)"는 2022년 발표된 이래 널리 권장되었지만 [1], 최근 연구에 따르면 이 기법은 이제 덜 중요해졌다 [2]. 이 글의 내용도 일부는 그런 운명을 맞을 것이다.
AI 에이전트 시스템을 위한 목표는 명확하고, 유용하고, 달성 가능해야 한다.
명확하다는 것은 테스트할 수 있을 만큼 구체적이라는 뜻이다. "개발자의 코딩 작업을 돕는다"는 목표가 아니라 범주다. 목표는 "GitHub 이슈 설명과 Python 저장소가 주어지면, 기존 테스트를 통과하는 PR을 생성한다" 같은 것이다. 후자에서는 어떤 입력을 준비해야 하는지, 어떤 출력을 평가해야 하는지, 평가 기준이 무엇인지가 드러난다. 목표의 범위를 좁혀야 한다. 범용 시스템은 평가하기 어렵고, 개선하기 어렵고, 제대로 작동하는지 알기도 어렵다. 좁은 범위에서 시스템이 잘 작동하면 범위를 넓히는 것을 고려할 수 있다.
유용하다는 것은 목표를 달성했을 때 실제 문제가 해결된다는 뜻이다. 이는 명확함과는 다른 개념이다. "코드베이스를 감사하여 보안 문제를 발견한다"는 잘 정의된 목표일 수 있고, 내 경험상 달성 가능하기도 하다. 하지만 이미 알고 있는 보안 문제를 해결하는 데도 허덕이고 있다면, 잠재적 오탐을 포함하는 더 많은 문제를 대기열에 추가하는 것은 유용하지 않다. 질문은 단순히 "이것을 할 수 있는가?"가 아니라 "이것이 실제로 원하는 것인가?"다.
달성 가능하다는 것은 현재 모델 능력을 감안했을 때 현실적이라는 뜻이다. SWE-bench Verified 같은 벤치마크는 현재 AI가 어떤 코딩을 할 수 있는지 대략적인 감을 준다. 다른 분야에도 비슷한 벤치마크가 있다. 목표를 달성하기 위해 현재 모델이 일관되게 실패하는 무언가를 안정적으로 해야 한다면 그것은 현실적으로 어려울 수 있다. 모델 능력은 꾸준히 발전하고 있으므로, 작업이 급하지 않다면 현재 한계에 맞춰 어떻게든 시스템을 구축하기보다 기다리는 것이 나을 수 있다.
인간 전문가가 목표를 달성하기 위해 무엇을 할지 모호함 없이 설명할 수 있는가? 결과물이 나오면 실제로 사용하겠는가? 그렇지 않다면, 작업을 시작하기 전에 목표를 더 다듬어야 한다.
측정할 수 없는 것은 개선할 수 없다. 평가는 에이전트에 가한 변경 -- 다른 모델, 새 프롬프트, 다른 도구 -- 이 상황을 좋아지게 했는지 나빠지게 했는지 판단하는 수단이다. 평가 없이는 눈을 감고 운전하는 것과 같다.
평가는 객관적인 것이 좋다. 목표가 "기존 테스트를 통과하는 PR을 생성한다"라면, 평가는 테스트를 실행하는 것이다. 테스트는 통과하거나 실패할 것이다. 객관적 평가는 빠르고, 저렴하고, 일관적이다. 목표를 객관적 기준을 중심으로 설계할 수 있다면, 그렇게 하라.
객관적 평가가 어렵다면 주관적 평가도 가능하다. 주관적 평가는 사람이 할 수도 있고 AI가 할 수도 있다 (LLM-as-a-judge). 두 경우 모두 채점 기준(scoring rubric)이 도움이 된다. 채점 기준이란 각 항목별로 어떤 것이 좋은 답변이고 어떤 것이 나쁜 답변인지 명확하게 설명한 기준 목록이다. 채점 기준이 없으면 평가자 간 일치도(inter-rater agreement)가 낮다. 동일한 출력을 두 평가자가 평가하면 의견이 갈리고, 같은 평가자도 시간이 지나면 기준이 흔들린다. 채점 기준은 여러 평가 실행 간에 점수를 비교 가능하게 한다. AI가 평가하는 경우에도 명확한 채점 기준을 받은 모델은 그렇지 않은 모델보다 더 일관된 점수를 준다.
평가가 반드시 갖춰야 할 두 가지 속성이 있다. 목표를 반영해야 하고, 속이기 어려워야 한다.
목표를 반영한다는 것은 평가에서 좋은 점수를 받으면 목표도 실제로 달성된다는 뜻이다. 실제와 동떨어진 평가는 에이전트를 엉뚱한 방향으로 최적화한다. 에이전트의 목표가 고객 지원 티켓 처리라면, 비슷해 보이지만 실제의 복잡함이 없고 단순한 합성 데이터보다 실제 고객 지원 티켓으로 평가하는 것이 바람직하다.
속이기 어렵다는 것은 에이전트가 지표를 조작해 좋은 점수를 받을 수 없어야 한다는 뜻이다. 평가가 "테스트를 통과하는가"를 측정하는데 에이전트가 테스트를 수정할 수 있다면, 지표를 믿을 수 없다. 적대적으로 생각할 필요가 있다. 에이전트가 좋은 점수를 받았다면, 그것이 항상 실제로 더 좋은 것인가? SWE-bench Verified는 교훈적인 사례다. OpenAI는 실패의 절반 이상이 테스트 결함 때문임을 발견했다. 어떤 테스트는 문제 설명에 언급되지 않은 특정 구현 세부사항을 강제했고, 다른 어떤 테스트는 명세되지 않은 기능을 테스트했다. 그 외에도, 테스트된 모든 프론티어 모델이 정답 패치를 암기해서 그대로 재현할 수 있었는데, 이는 훈련 데이터가 오염되었음을 시사한다. 그 결과 OpenAI는 SWE-bench Verified 점수 보고를 중단했다 [3].
작게 시작하라. 개발 초기에는 평가 예시 열 개로도 충분한 경우가 많다. 초기에는 에이전트가 작동하지 않는 상태에서 작동하는 상태로 전환되고 있으므로, 열 개의 예시만으로도 변화를 감지할 수 있다. 에이전트가 성숙해 더 작은 점진적인 개선을 하게 되면 열 개의 예시로는 감지가 어려워진다. 감지하려는 개선이 작아질수록 평가 예시를 늘려야 한다.
에이전트의 로그는 큰 가치가 있다. 실패한 에이전트의 로그를 읽어보는 것만으로도 많은 것을 알 수 있다. 모델은 생성하면서 생각하기 때문에 그 사고 과정이 로그에 남는다. 그러한 로그를 읽으면 모델이 도구 결과를 잘못 읽고, 잘못된 가정을 하고, 이후 여러 턴에 걸쳐 잘못된 가정을 고수하는 모습을 볼 수 있다. 이것은 다른 방법으로는 얻을 수 없는 귀한 정보이며, 그렇기 때문에 로그에는 투자할 가치가 있다.
최소한 모델의 모든 상호작용을 기록해야 한다. 기록해야 하는 항목으로 사용한 모델, 전체 입력 (시스템 프롬프트와 도구 정의 포함), 전체 출력, 소요 시간, 비용이 있다. 비용 추적을 하지 않으면 나중에 재구성하기 어렵다. 지연 시간 데이터는 모델이나 프롬프트 변경을 비교해 속도와 품질 간의 트레이드오프를 분석해야 할 때 꼭 필요하다.
로그는 사람이 직접 살펴보는 것과 자동화된 분석을 지원해야 한다. 사람이 직접 살펴보려면 로그를 보기 쉬운 형태로 읽을 수 있어야 하고 시간, 작업, 결과, 비용 등으로 검색할 수 있어야 한다. 자동화된 분석을 위해서는 모델이 질의할 수 있는 구조화된 형식으로 데이터가 존재해야 한다. 텍스트 파일로만 존재하는 로그는 개별 실패를 디버깅하는 데 유용하지만, 질의 가능한 형식으로 저장된 로그는 통계적인 질문을 할 수 있게 한다. 어떤 작업의 실패율이 가장 높은가? 어떤 프롬프트가 가장 긴 추론을 만드는가? 성공한 실행당 평균 비용은 얼마인가?
AI 에이전트 로그 관리를 위한 도구들이 있다. Langfuse [4]와 Logfire [5] 모두 살펴볼 가치가 있다. 하지만 기존 도구가 해결해 주지 않는 필요가 있다면 직접 도구를 만드는 것도 생각해봐야 한다. 그것은 독립적인 도구일 수도 있고 기존 플랫폼 위에 구축된 것일 수도 있다.
로그를 나중에 추가할 인프라로 생각해서는 안된다. 로그가 없는 고통을 느낄 때가 되면, 가장 큰 도움이 되었을 로그는 이미 잃어버린 뒤다.
에이전트를 개선하기 위해 모델, 프롬프트, 도구를 바꿀 수 있다.
모델은 시스템 성능에서 가장 중요한 요소다. 더 좋은 모델은 평범한 프롬프트를 구제할 수 있지만, 나쁜 모델은 완벽한 프롬프트로도 구제할 수 없다. 새로운 모델은 계속해서 나온다. 핵심은 새 모델을 빠르게 테스트할 수 있어야 한다는 것이다. 모델을 교체하고, 평가를 실행하고, 점수를 비교한다. 평가가 잘 갖춰져 있다면 이 작업은 며칠이 아니라 몇십 분이 걸려야 한다. 모델 평가가 쉬워야 새 모델을 빠르게 적용할 수 있다.
프롬프트는 일상적인 개선이 일어나는 곳이다. 프롬프트를 개선하는 올바른 방법은 모델이 원하는 것을 상상하는 것이 아니라 로그를 읽는 것이다. 실패한 실행의 로그는 보통 모델이 무엇을 오해했는지, 프롬프트의 어떤 부분이 전달되지 않았는지 보여준다. 변경사항은 평가로 검증해야 한다. 어떤 실패를 고치는 프롬프트 변경이 다른 어떤 경우를 조용히 망가뜨릴 수 있다.
도구는 모델과 세상 사이의 인터페이스이며, 사용자 인터페이스처럼 주의 깊게 설계해야 한다. 설계의 목표는 올바른 사용을 쉽게 하고 잘못된 사용을 어렵게 만드는 것이다. 모델이 도구를 자주 잘못 사용한다면 -- 인자를 잘못된 형식으로 전달하거나, 잘못된 맥락에서 호출하거나, 출력을 오해한다면 -- 그것은 모델의 문제가 아니라 도구의 문제다. 사용자가 계속 같은 실수를 하면 사용자가 아니라 UI를 다시 설계하듯이, 모델이 의도하지 않은 행동을 계속하면 모델에 맞춰주는 것이 좋을 수 있다.
세 가지 모두 직관보다는 평가로 변경하는 것이 바람직하다. 무엇이 도움이 될지에 대한 직관은 자주 틀리지만, 평가 점수는 그렇지 않다.
언어 모델은 세상에 대한 방대한 지식을 가지고 있다. 프로그래밍 언어와 과학의 개념과 역사적 사실을 이해한다. 하지만 우리 조직과 코드베이스, 내부 도구, 해당 분야의 관습에 대해서는 잘 모른다. 모델의 잘못이 아니라 알려주지 않았기 때문이다.
실용적인 해결책은 모델에게 필요한 것을 주는 것이다. 정보 소스와 사용법을 제공해야 한다. 에이전트가 내부 데이터베이스를 질의해야 한다면, 그렇게 할 수 있는 CLI를 주고 사용법 문서도 같이 준다. 코드베이스 특유의 관습을 따라야 한다면, 그 관습을 파일에 적어 둔다. 지식 베이스를 참조해야 한다면, 검색 도구를 주고 스키마를 설명한다. 모델의 추론 능력보다 추론할 재료가 문제인 경우가 많다.
Anthropic은 이 패턴을 에이전트 스킬 [6]로 공식화했다. 스킬은 지침이 담긴 SKILL.md 파일과 지원 스크립트 및 리소스로 구성된 폴더다. 시작할 때 에이전트는 설치된 각 스킬의 이름과 설명만 미리 읽어둔다. 작업이 관련 스킬을 트리거하면, 에이전트는 전체 지침과 링크된 파일을 필요에 따라 읽는다. 이 점진적 공개 설계 덕분에 컨텍스트 윈도에는 한계가 있지만 스킬에는 그보다 많은 컨텍스트를 담을 수 있다.
Anthropic의 스킬 형식을 사용하지 않더라도, 아이디어는 일반적으로 적용할 수 있다.. 에이전트에게 필요하지만 일반 지식으로는 유추할 수 없는 컨텍스트가 무엇인지 파악하고, 그 컨텍스트를 발견 가능한 리소스로 패키징하고, 에이전트가 필요에 따라 접근할 수 있는 도구를 주어라.
새 모델과 큰 모델이 능사는 아니다. 프론티어 모델은 비싸고 느리다. 에이전트 시스템 내의 많은 작업은 더 작은 모델로 충분하다. 실용적인 접근법은 각 작업을 안정적으로 할 수 있는 가장 작은 모델을 사용하는 것이다. 여러 모델을 대상으로 평가를 실행해 변곡점을 찾고, 그보다 한 단계 위의 모델을 쓰면 된다.
출력 토큰은 입력 토큰보다 비싸다. 따라서 입력 토큰보다 출력 토큰을 아껴야 한다. 필요한 것만 요청해 출력을 최소화하라. 작업을 위해 무거운 처리 전에 분류나 필터링이 필요하다면, 가벼운 단계를 먼저 하라. 천 개의 항목을 분류해 깊게 분석할 가치 있는 스무 개를 찾는 것은 천 개 모두 전체 분석을 실행하는 것보다 훨씬 저렴하다. 그리고 분류 단계는 분석 단계보다 더 작은 모델을 쓸 수 있는 경우가 많다.
프롬프트 캐싱은 입력 비용을 줄이는 가장 효과적인 수단 중 하나다. OpenAI와 Anthropic 모두 반복되는 프롬프트 접두사를 캐싱하므로, 매 요청 앞에 등장하는 내용 -- 시스템 프롬프트와 도구 정의 -- 은 한 번 캐싱되면 이후 호출에서 훨씬 저렴해진다. 안정적인 내용을 컨텍스트 앞에 두고 호출 사이에 편집하지 마라. 컨텍스트 편집 -- 대화의 앞부분을 재배열하거나, 요약하거나, 다듬는 것 -- 은 캐시를 파괴하므로 신중하게 접근해야 한다.
해야할 일을 배치 작업으로 구조화할 수 있다면 -- 실시간 요건 없이 처리되는 많은 독립적 입력 -- OpenAI와 Anthropic 모두 상당한 할인율로 배치 API를 제공한다. 배치 처리는 대화형 에이전트에는 적합하지 않지만, 평가 실행, 대규모 분류 작업, 지연 시간 제약이 없는 워크로드에서 비용을 크게 줄일 수 있다.
멀티 에이전트 시스템은 단순히 병렬로 실행하는 방법이 아니다. 두 가지 목적이 있다. 적당한 크기로 작업을 분해하는 것, 그리고 희소하고 제한된 자원인 컨텍스트 윈도를 아끼는 것이다.
컨텍스트 윈도 제약을 과소평가하는 경우가 많다. 컨텍스트 윈도 안의 모든 것이 모델의 주의를 두고 경쟁한다. 모든 중간 결과, 모든 도구 응답, 탐색하다 막힌 모든 막다른 길. 하나의 에이전트가 큰 작업을 처리하면 이 모든 것이 한 곳에 쌓인다. 정작 중요한 부분에 다다를 때쯤이면, 이전 단계에서 나온 무관하거나 오히려 방해가 되는 자료들로 컨텍스트가 가득 차 있다. 별도의 에이전트는 각자 자신의 작업에만 관련된 깔끔하고 집중된 컨텍스트를 갖는다.
작업 분해가 또 다른 이유다. 하나의 에이전트가 잘 처리하기에 너무 큰 작업은 보통 상호 의존성이 적은 하위 작업으로 나눌 수 있다. 오케스트레이터의 역할은 그 구조를 파악하는 것이다. 어떤 부분이 독립적으로 진행될 수 있는지, 어떤 것이 순서를 지켜야 하는지, 어떤 결과를 마지막에 종합해야 하는지. 이것은 단순한 프롬프팅 문제가 아니라 설계의 문제이다.
멀티 에이전트 아키텍처가 항상 올바른 선택은 아니다. 작업이 본질적으로 순차적이라면 -- 각 단계에서 이전의 모든 것에 대한 완전한 지식이 필요하다면 -- 에이전트를 분리해도 얻을 것이 거의 없고 문제점만 많아진다. 넓은 작업, 즉 병렬로 진행되다가 마지막에 종합하는 작업이 잘 맞는다. 단계 간 상호 의존성이 강한 촘촘하게 결합된 작업은 그렇지 않다.
멀티 에이전트 시스템은 비싸다. Anthropic에 따르면 멀티 에이전트 연구 시스템은 표준 채팅보다 약 15배 많은 토큰을 사용했다 [7]. 작업이 충분히 복잡하고 출력이 가치 있을 때만 그러한 비용이 정당화될 수 있다. 단일 에이전트로 처리할 수 있는 작업을 멀티 에이전트 시스템으로 하는 것은 낭비일 뿐이다.
서브에이전트는 오케스트레이터가 특정 하위 작업을 처리하기 위해 생성하는 에이전트이다. 별도의 컨텍스트 윈도와 도구, 실행 루프를 갖는다. 오케스트레이터는 작업을 위임하고, 결과를 기다리고, 그 결과를 자신의 컨텍스트에 통합한다.
서브에이전트에는 명확한 종료 조건이 필요하다. 완료되었음을 알리고 오케스트레이터가 사용할 수 있는 결과를 내놓는 무언가가 있어야 한다. 가장 깔끔한 메커니즘은 전용 출력 도구다. 모델이 출력 도구를 호출하면 실행이 끝나고 결과가 반환된다. 이것은 서브에이전트의 마지막 응답을 출력으로 사용하는 것보다 낫다. 명시적이고, 구조화되어 있고, 파싱하기 쉽기 때문이다.
Armin Ronacher는 모델이 출력 도구를 호출하지 못하는 경우가 있다고 지적한다 [8]. 이것은 실제 문제지만 해결할 수 없는 문제는 아니다. OpenAI와 Anthropic API 모두 특정 도구를 강제로 호출하게 할 수 있는 tool_choice 파라미터를 지원한다. 서브에이전트 실행이 끝날 때 작업을 마친 후 tool_choice를 출력 도구로 설정해 마지막 API 호출을 할 수 있다. 이렇게 하면 모델이 스스로 출력 도구를 호출하지 않으려 하더라도 구조화된 출력을 내도록 강제할 수 있다.
더 까다로운 문제는 실패다. 서브에이전트는 실패할 수 있으며, 가장 큰 피해를 주는 실패 방식은 명확한 오류가 아니라 진전 없이 길게 이어지는 실행이다. 문제가 되는 것은 오류의 증폭이다. 모델이 도구 결과를 잘못 읽고, 잘못된 방향으로 나아가고, 이후의 각 단계가 그 잘못된 기반 위에 쌓인다. 이런 실행은 턴 수 측면에서 가장 긴 경향이 있다. 성공할 서브에이전트는 대개 예측 가능한 턴 수 안에 성공한다. 그 지점을 넘어서도 계속 가는 것은 대개 막힌 것이다.
실용적인 해결책은 턴수 제한이다. 턴수 제한은 에이전트를 여러 작업에 실행해보고 성공적인 실행이 어디서 끝나는지 관찰해서 경험적으로 결정한다. 제한에 도달하면, 실행을 계속하게 두는 대신 포기하고 다시 시도한다. 깔끔한 컨텍스트로 새로 시작하면 길게 늘어진 실행이 실패할 곳에서 성공하는 경우가 많다. 이것은 에이전트가 점진적으로 진전을 이루고 있다고 생각한다면 직관에 반하지만, 오류 증폭은 막힌 에이전트가 나아지는 것이 아니라 종종 나빠지고 있음을 의미한다.
턴수 제한은 개발 중에 유용하기도 하다. 에이전트가 일상적으로 제한에 도달한다면, 그것은 작업 분해가 손질이 필요하다는 신호이거나, 도구가 모델에게 필요한 것을 주지 않고 있거나, 프롬프트가 언제 작업이 완료되었는지 충분히 명확하지 않다는 신호이다.
에이전트가 도구로 복잡한 작업을 해야 할 때 -- 여러 도구를 순서대로 호출하거나, 큰 결과를 필터링하거나, 항목 목록을 반복 처리하는 것 -- 단순한 접근법은 모델이 도구를 하나씩 호출하고, 호출 사이마다 모델을 거치는 것이다. 이것은 작동하지만 비싸고 느리다. 더 나은 방법이 있다. 모델에게 그 모든 것을 하는 코드를 생성하게 한 다음 코드를 실행하는 것이다.
이것이 가능한 이유는 언어 모델이 코드 생성에 유독 뛰어나기 때문이다. 언어 모델은 훈련에서 도구 호출보다 훨씬 많은 실제 코드를 보았다. 도구를 프로그래밍 언어의 호출 가능한 함수로 제시하면, 모델은 프로그래머가 그러듯이 반복문, 조건문, 오류 처리에 대해 추론할 수 있다. Cloudflare는 Code Mode [9]에서 명시적으로 그렇게 주장한다. 도구 호출은 모델이 드물게 접하는 패턴에 의존하지만, 코드 생성은 모델이 깊이 내면화한 패턴에 의존한다.
코드 생성의 토큰 절약 효과는 크다. 전통적인 도구 호출 루프에서는 모든 중간 결과가 모델의 컨텍스트 윈도를 거친다. 2시간짜리 회의 녹취를 가져와 CRM에 첨부하면, 전체 녹취가 컨텍스트에 두 번 들어간다. 20명 직원의 예산 데이터를 하나씩 조회하면, 요약하기 전에 20개의 응답이 모두 컨텍스트에 적재된다. 코드 생성을 사용하면 중간 결과가 실행 환경에 머물고, 최종 출력 -- 필터링된 요약, 합계 -- 만 모델에게 돌아간다. Anthropic은 대표적인 사례에서 토큰 사용량을 15만에서 2천으로 줄였다고 보고한다 [10].
실용적인 구현에는 세 가지가 필요하다.
코드 실행 환경. 생성된 코드가 어딘가에서 실행되어야 한다. 샌드박스가 필요하다. 네트워크 접근을 제한하고, 의도한 것 이외의 파일시스템 접근을 금지해야 한다. Cloudflare는 V8 isolate를 사용하고, Anthropic은 Python 컨테이너를 사용한다. 직접 구축한다면 인프라가 간단하지는 않지만, 샌드박스는 일반적으로 사용할 수 있다.
함수로 노출된 도구. 모델은 어떤 함수가 사용 가능하고 무엇을 반환하는지 알아야 한다. 출력 형식에 대한 설명이 중요하다. 도구가 JSON을 반환한다면 스키마를 설명하라. 모델이 코드를 작성하려면 기대해야 하는 결과를 알아야 한다.
도구별 옵트인. 모든 도구가 생성된 코드에서 호출 가능해야 하는 것은 아니다. Anthropic의 API는 각 도구 정의의 allowed_callers 필드로 이를 구현한다 [11]. 모델이 직접 호출하는 도구와 코드에서 호출하는 도구를 구분한다. 이 구분은 보안상 중요하다. 부작용이 있거나 민감한 출력을 가진 도구는 두 맥락에서 다른 처리가 필요할 수 있다.
도구 사용 외에도 같은 원칙이 적용된다. 에이전트가 데이터를 처리해야 할 때 -- 파일을 변환하거나, 질의 결과를 집계하거나, 목록을 필터링하는 -- 코드를 작성하게 하고 그 코드를 실행하는 것이 자연어로 데이터에 대해 추론하게 하는 것보다 나은 경우가 많다. 모델의 코드 생성 능력은 코딩 에이전트만을 위한 기능이 아니라 기본적인 도구이다.
이 패턴을 채택하고 싶다면, MCPorter [12]가 도움이 될 수 있다. MCPorter는 MCP 서버의 도구 정의에서 TypeScript 래퍼를 생성하는 오픈 소스 TypeScript 라이브러리이다.
한 가지 주의사항이 있다. 이 패턴은 실행 환경이 진정으로 격리되어 있어야 한다. 생성된 코드는 신뢰할 수 없는 입력이다. 에이전트가 악의적인 코드를 생성하게 하는 프롬프트로 공격당할 수 있다. 샌드박싱은 선택사항이 아니다.
에이전트가 기계가 읽을 수 있는 출력을 내놓아야 할 때는 -- 분류, 결정, 필드 추출 -- 구조화된 출력이 올바른 도구다. 텍스트를 파싱하는 대신, 스키마를 정의하고 모델이 채운다. 더 신뢰할 수 있고, 테스트하기 더 쉽고, 파싱 버그를 통째로 제거한다.
언어 모델은 토큰을 왼쪽에서 오른쪽으로 순서대로 생성한다. 스키마를 {"answer": "..."} 로 정의하면, 모델은 바로 답을 정한다. {"reasoning": "...", "answer": "..."} 로 정의하면, 모델은 먼저 추론하도록 강제되고 그 추론이 답에 영향을 미친다. 추론 필드가 스키마에서 답 필드보다 앞에 오므로, 출력에서도 답 앞에 온다.
나중에 추론을 완전히 버리고 답만 사용해도 된다. 성능상의 이점은 추론을 읽는 것이 아니라 모델이 추론을 생성했다는 데서 온다. 이 방법은 특별한 모델 지원 없이 추론 모델과 같은 효과를 얻을 수 있게 해 준다.
에이전트가 파일을 수정해야 한다면 파일 편집을 어떻게 구현하느냐가 시스템 성능에 중요한 영향을 미친다.
이것은 내 경험만이 아니다. Anthropic은 파일 편집 신뢰성을 명시적으로 어려운 문제 중 하나로 꼽았다 [13]. Anthropic이 API로 제공하는 텍스트 편집기 도구 [14]를 보면, str_replace 명령은 정확한 문자열 일치를 필요로 하며, 하니스는 문자열이 일치하지 않거나 여러 번 일치할 때 오류를 반환해야 한다. 문제가 충분히 어렵기 때문에 Anthropic은 도구 설계에 우회책을 내장했다 (예를 들어 파일의 절대 경로를 요구하는 것은 명시적인 오류 방지 조치다).
어려운 점은 모델이 원하는 변경에 대해 추론할 뿐 아니라, 모호함이나 오류 없이 파일에 기계적으로 적용할 수 있는 형식으로 출력을 내놓아야 한다는 것이다. 이것은 서로 다른 일이며, 어떤 형식을 선택하느냐에 따라 기계적인 적용 단계가 얼마나 자주 실패하는지가 달라진다.
현재 사용되는 주요 접근법은 다음과 같다.
전체 파일 재작성. 모델이 파일의 내용을 완전히 새로 출력한다. 구현하고 파싱하기 단순하며, 형식 오류로 실패하지 않는다. 단점은 비용(출력 토큰이 파일 크기에 비례해 증가함)과 주변 컨텍스트 손실이다. 작은 파일에서만 실용적이다.
문자열 교체. 모델이 이전 문자열과 새 문자열을 출력하면, 하니스가 찾아서 교체한다. Anthropic이 사용하는 방식이다 [14]. 실패 방식은 잘 알려져 있다. 모델은 공백과 들여쓰기를 포함해 이전 문자열을 글자 하나 하나 그대로 재현해야 하는데, 이것을 자주 틀린다. "교체할 문자열을 찾지 못했다"는 오류는 에이전트 실패의 흔한 원인이다.
patch/diff 형식. 모델이 변경사항을 설명하는 구조화된 diff를 출력한다. OpenAI의 Codex는 *** Begin Patch 와 *** End Patch 마커가 있는 커스텀 패치 형식을 사용한다. 그 자체로는 쉽게 망가지지만 Codex는 제약된 샘플링(constrained sampling)으로 이를 해결한다. 패치 형식을 Lark 문맥 자유 문법(context free grammar)으로 표현하고, 추론 시 모델 출력을 문법에 맞게 제한한다 [15]. 이것은 형식 오류를 통째로 제거한다. 이것이 OpenAI의 공개 API를 사용해 이루어진다는 점이 중요하다 [16]. 이 기법은 누구나 사용할 수 있다.
훈련된 병합 모델. Cursor는 모델의 편집 의도를 원본 파일과 병합하는 별도의 70B 모델을 훈련했다. 병합 견고성을 학습된 능력으로 만들어 형식 문제를 완전히 우회한다. 명백한 비용은 전용 모델을 훈련하고 서빙하는 데 상당한 자원이 필요하다는 것이다.
Can Bölük은 16개 모델을 180개 과제에서 벤치마킹하여 형식 선택만으로도 성공률이 달라질 수 있음을 보였다 [17]. 그의 글은 이 장과 함께 읽을 가치가 있다. 그가 제안한 형식은 각 줄에 줄 번호와 짧은 해시를 태그한다. 주요 이점은 모델이 정확한 내용을 재현하지 않고 식별자로 줄을 참조할 수 있다는 것인데, 이것이 모델에게는 훨씬 쉽다. 해시는 줄 번호에 더해서 체크섬 역할을 한다. 이전 편집으로 줄이 밀렸다면, 예상 해시와 실제 줄 내용 사이의 불일치가 잘못된 줄을 조용히 편집하는 대신 오류를 잡아낸다.
에이전트에게 도구를 준다는 것은 세상에서 실제 행동을 취할 수 있는 능력을 주는 것이다 -- 파일 읽기, 파일 쓰기, 명령 실행, 외부 서비스 호출. 도구 인가 제어는 에이전트가 자율적으로 취할 수 있는 행동과 사람의 승인이 필요한 행동을 결정하는 방법이다. 이것을 제대로 하는 것은 안전과 사용성 모두에 중요하다. 너무 제한적이면 에이전트가 일을 할 수 없고, 너무 허용적이면 모르는 사이에 피해를 줄 수 있는 자율 시스템이 된다.
먼저 이해해야 할 것은 인가와 샌드박싱이 상호 보완적이며 서로 대체할 수 없다는 것이다. 인가는 에이전트가 무엇을 하기로 결정하는지를 제어하며 에이전트 수준에서 작동한다. 샌드박싱은 에이전트가 무엇을 결정하든 관계없이 OS 수준에서 제한을 강제한다. Claude Code의 문서 [18]는 이 구분을 명확히 한다. 인가는 에이전트가 제한된 행동을 시도하는 것을 막고, 샌드박싱은 에이전트가 제한된 행동을 시도하더라도 그러한 행동이 실제로 실행되는 것을 막는다. 둘 다 사용해야 한다.
덜 명백한 점은 Bash 인가 규칙이 보이는 것보다 강한 점도 있고 약한 점도 있다는 것이다.
보이는 것보다 강한 이유는 셸 명령이 문자열로만 매칭되지 않고 파싱되기 때문이다. Claude Code는 오픈 소스가 아니지만, Bun을 사용한다고 알려져 있는데, Bun에는 셸 파서가 포함되어 있다. Codex(오픈 소스)는 Tree-sitter의 Bash 파서로 같은 작업을 한다 [19]. 스크립트가 완전한 AST로 파싱되고, 단순한 명령 이외의 것이 포함되면 파싱이 거부된다. 허용된 연산자 (&&, ||, ;, |)는 각 개별 명령을 추출하고 각각을 인가 규칙과 별도로 확인하는 방식으로 처리된다. 즉 Bash(safe-cmd *)는 safe-cmd && malicious-cmd를 허용하지 않는다. 파서가 두 개의 명령을 보고 둘 다 확인한다.
보이는 것보다 약한 이유는 명령 이름 수준에서 안전성을 알 수 없기 때문이다. 고전적인 예시가 있다. rm을 거부하고 find를 허용해도 파일 삭제가 막히지 않는다. find에는 -delete 옵션이 있기 때문이다. 많은 유닉스 명령이 이처럼 다목적이다. 특정 명령이 안전하다는 가정 하에 작성된 단순한 허용 목록은 이러한 구멍이 생기는 경향이 있으며, 에이전트나 프롬프트 인젝션을 통해 에이전트를 제어하는 공격자는 그러한 구멍을 찾아낼 수 있다.
코딩 에이전트를 위한 실용적인 인가 모델은 이런 모습일 수 있다. 읽기 작업은 승인이 필요 없다. 파일 편집은 세션당 한 번 승인이 필요하다. 셸 명령은 명령당 승인이 필요하되, 테스트 실행이나 프로젝트 빌드 같은 일반적이고 안전한 작업은 미리 승인된 허용 목록에 넣는다.
파일이나 웹를 읽는 에이전트는 그 내용으로부터 공격자의 지시를 받을 수 있다. 엄격한 인가 규칙이 주요 방어책이다. 데이터를 유출하라는 지시는 에이전트가 외부 URL에 도달할 수 없다면 성공할 수 없다.
[1] Takeshi Kojima et al., "Large Language Models are Zero-Shot Reasoners", 2022-05-24. https://arxiv.org/abs/2205.11916
[2] Lennart Meincke et al., "Prompting Science Report 2: The Decreasing Value of Chain of Thought in Prompting", 2025-06-08. https://arxiv.org/abs/2506.07142
[3] OpenAI, "Why SWE-bench Verified no longer measures frontier coding capabilities", 2026-02-23. https://openai.com/index/why-we-no-longer-evaluate-swe-bench-verified/
[4] Langfuse. https://langfuse.com/
[5] Pydantic Logfire. https://pydantic.dev/logfire
[6] Agent Skills. https://agentskills.io/
[7] Anthropic, "How we built our multi-agent research system", 2025-06-13. https://www.anthropic.com/engineering/multi-agent-research-system
[8] Armin Ronacher, "Agent Design Is Still Hard", 2025-11-21. https://lucumr.pocoo.org/2025/11/21/agents-are-hard/
[9] Cloudflare, "Code Mode: the better way to use MCP", 2025-09-26. https://blog.cloudflare.com/code-mode/
[10] Anthropic, "Code execution with MCP: Building more efficient agents", 2025-11-04. https://www.anthropic.com/engineering/code-execution-with-mcp
[11] Anthropic, "Programmatic tool calling". https://platform.claude.com/docs/en/agents-and-tools/tool-use/programmatic-tool-calling
[12] Peter Steinberger, MCPorter. https://github.com/steipete/mcporter
[13] Anthropic, "Raising the bar on SWE-bench Verified with Claude 3.5 Sonnet", 2025-01-06. https://www.anthropic.com/engineering/swe-bench-sonnet
[14] Anthropic, "Text editor tool". https://platform.claude.com/docs/en/agents-and-tools/tool-use/text-editor-tool
[15] OpenAI, codex-rs/core/src/tools/handlers/apply_patch.rs, tool_apply_patch.lark. https://github.com/openai/codex
[16] OpenAI, "Function calling". https://developers.openai.com/api/docs/guides/function-calling
[17] Can Bölük, "I Improved 15 LLMs at Coding in One Afternoon. Only the Harness Changed.", 2026-02-12. https://blog.can.ac/2026/02/12/the-harness-problem/
[18] Anthropic, "Configure permissions". https://code.claude.com/docs/en/permissions
[19] OpenAI, codex-rs/shell-command/src/bash.rs. https://github.com/openai/codex
이 글은 AI 에이전트 시스템을 만들며 쌓은 경험을 정리한 것으로, 2026년 2월에 썼다. 두 부분으로 구성된다. 첫 번째 부분은 총론이고, 두 번째 부분은 각론이다.
이 분야는 빠르게 변하고 있어, 여기에 쓴 교훈도 금방 낡을 수 있다. 컨텍스트 윈도는 이 글 전반에 걸쳐 반복되는 제약이지만, 미래에는 그렇지 않을 수도 있다. "차근차근 생각하라(Let's think step by step)"는 2022년 발표된 이래 널리 권장되었지만 [1], 최근 연구에 따르면 이 기법은 이제 덜 중요해졌다 [2]. 이 글의 내용도 일부는 그런 운명을 맞을 것이다.
AI 에이전트 시스템을 위한 목표는 명확하고, 유용하고, 달성 가능해야 한다.
명확하다는 것은 테스트할 수 있을 만큼 구체적이라는 뜻이다. "개발자의 코딩 작업을 돕는다"는 목표가 아니라 범주다. 목표는 "GitHub 이슈 설명과 Python 저장소가 주어지면, 기존 테스트를 통과하는 PR을 생성한다" 같은 것이다. 후자에서는 어떤 입력을 준비해야 하는지, 어떤 출력을 평가해야 하는지, 평가 기준이 무엇인지가 드러난다. 목표의 범위를 좁혀야 한다. 범용 시스템은 평가하기 어렵고, 개선하기 어렵고, 제대로 작동하는지 알기도 어렵다. 좁은 범위에서 시스템이 잘 작동하면 범위를 넓히는 것을 고려할 수 있다.
유용하다는 것은 목표를 달성했을 때 실제 문제가 해결된다는 뜻이다. 이는 명확함과는 다른 개념이다. "코드베이스를 감사하여 보안 문제를 발견한다"는 잘 정의된 목표일 수 있고, 내 경험상 달성 가능하기도 하다. 하지만 이미 알고 있는 보안 문제를 해결하는 데도 허덕이고 있다면, 잠재적 오탐을 포함하는 더 많은 문제를 대기열에 추가하는 것은 유용하지 않다. 질문은 단순히 "이것을 할 수 있는가?"가 아니라 "이것이 실제로 원하는 것인가?"다.
달성 가능하다는 것은 현재 모델 능력을 감안했을 때 현실적이라는 뜻이다. SWE-bench Verified 같은 벤치마크는 현재 AI가 어떤 코딩을 할 수 있는지 대략적인 감을 준다. 다른 분야에도 비슷한 벤치마크가 있다. 목표를 달성하기 위해 현재 모델이 일관되게 실패하는 무언가를 안정적으로 해야 한다면 그것은 현실적으로 어려울 수 있다. 모델 능력은 꾸준히 발전하고 있으므로, 작업이 급하지 않다면 현재 한계에 맞춰 어떻게든 시스템을 구축하기보다 기다리는 것이 나을 수 있다.
인간 전문가가 목표를 달성하기 위해 무엇을 할지 모호함 없이 설명할 수 있는가? 결과물이 나오면 실제로 사용하겠는가? 그렇지 않다면, 작업을 시작하기 전에 목표를 더 다듬어야 한다.
측정할 수 없는 것은 개선할 수 없다. 평가는 에이전트에 가한 변경 -- 다른 모델, 새 프롬프트, 다른 도구 -- 이 상황을 좋아지게 했는지 나빠지게 했는지 판단하는 수단이다. 평가 없이는 눈을 감고 운전하는 것과 같다.
평가는 객관적인 것이 좋다. 목표가 "기존 테스트를 통과하는 PR을 생성한다"라면, 평가는 테스트를 실행하는 것이다. 테스트는 통과하거나 실패할 것이다. 객관적 평가는 빠르고, 저렴하고, 일관적이다. 목표를 객관적 기준을 중심으로 설계할 수 있다면, 그렇게 하라.
객관적 평가가 어렵다면 주관적 평가도 가능하다. 주관적 평가는 사람이 할 수도 있고 AI가 할 수도 있다 (LLM-as-a-judge). 두 경우 모두 채점 기준(scoring rubric)이 도움이 된다. 채점 기준이란 각 항목별로 어떤 것이 좋은 답변이고 어떤 것이 나쁜 답변인지 명확하게 설명한 기준 목록이다. 채점 기준이 없으면 평가자 간 일치도(inter-rater agreement)가 낮다. 동일한 출력을 두 평가자가 평가하면 의견이 갈리고, 같은 평가자도 시간이 지나면 기준이 흔들린다. 채점 기준은 여러 평가 실행 간에 점수를 비교 가능하게 한다. AI가 평가하는 경우에도 명확한 채점 기준을 받은 모델은 그렇지 않은 모델보다 더 일관된 점수를 준다.
평가가 반드시 갖춰야 할 두 가지 속성이 있다. 목표를 반영해야 하고, 속이기 어려워야 한다.
목표를 반영한다는 것은 평가에서 좋은 점수를 받으면 목표도 실제로 달성된다는 뜻이다. 실제와 동떨어진 평가는 에이전트를 엉뚱한 방향으로 최적화한다. 에이전트의 목표가 고객 지원 티켓 처리라면, 비슷해 보이지만 실제의 복잡함이 없고 단순한 합성 데이터보다 실제 고객 지원 티켓으로 평가하는 것이 바람직하다.
속이기 어렵다는 것은 에이전트가 지표를 조작해 좋은 점수를 받을 수 없어야 한다는 뜻이다. 평가가 "테스트를 통과하는가"를 측정하는데 에이전트가 테스트를 수정할 수 있다면, 지표를 믿을 수 없다. 적대적으로 생각할 필요가 있다. 에이전트가 좋은 점수를 받았다면, 그것이 항상 실제로 더 좋은 것인가? SWE-bench Verified는 교훈적인 사례다. OpenAI는 실패의 절반 이상이 테스트 결함 때문임을 발견했다. 어떤 테스트는 문제 설명에 언급되지 않은 특정 구현 세부사항을 강제했고, 다른 어떤 테스트는 명세되지 않은 기능을 테스트했다. 그 외에도, 테스트된 모든 프론티어 모델이 정답 패치를 암기해서 그대로 재현할 수 있었는데, 이는 훈련 데이터가 오염되었음을 시사한다. 그 결과 OpenAI는 SWE-bench Verified 점수 보고를 중단했다 [3].
작게 시작하라. 개발 초기에는 평가 예시 열 개로도 충분한 경우가 많다. 초기에는 에이전트가 작동하지 않는 상태에서 작동하는 상태로 전환되고 있으므로, 열 개의 예시만으로도 변화를 감지할 수 있다. 에이전트가 성숙해 더 작은 점진적인 개선을 하게 되면 열 개의 예시로는 감지가 어려워진다. 감지하려는 개선이 작아질수록 평가 예시를 늘려야 한다.
에이전트의 로그는 큰 가치가 있다. 실패한 에이전트의 로그를 읽어보는 것만으로도 많은 것을 알 수 있다. 모델은 생성하면서 생각하기 때문에 그 사고 과정이 로그에 남는다. 그러한 로그를 읽으면 모델이 도구 결과를 잘못 읽고, 잘못된 가정을 하고, 이후 여러 턴에 걸쳐 잘못된 가정을 고수하는 모습을 볼 수 있다. 이것은 다른 방법으로는 얻을 수 없는 귀한 정보이며, 그렇기 때문에 로그에는 투자할 가치가 있다.
최소한 모델의 모든 상호작용을 기록해야 한다. 기록해야 하는 항목으로 사용한 모델, 전체 입력 (시스템 프롬프트와 도구 정의 포함), 전체 출력, 소요 시간, 비용이 있다. 비용 추적을 하지 않으면 나중에 재구성하기 어렵다. 지연 시간 데이터는 모델이나 프롬프트 변경을 비교해 속도와 품질 간의 트레이드오프를 분석해야 할 때 꼭 필요하다.
로그는 사람이 직접 살펴보는 것과 자동화된 분석을 지원해야 한다. 사람이 직접 살펴보려면 로그를 보기 쉬운 형태로 읽을 수 있어야 하고 시간, 작업, 결과, 비용 등으로 검색할 수 있어야 한다. 자동화된 분석을 위해서는 모델이 질의할 수 있는 구조화된 형식으로 데이터가 존재해야 한다. 텍스트 파일로만 존재하는 로그는 개별 실패를 디버깅하는 데 유용하지만, 질의 가능한 형식으로 저장된 로그는 통계적인 질문을 할 수 있게 한다. 어떤 작업의 실패율이 가장 높은가? 어떤 프롬프트가 가장 긴 추론을 만드는가? 성공한 실행당 평균 비용은 얼마인가?
AI 에이전트 로그 관리를 위한 도구들이 있다. Langfuse [4]와 Logfire [5] 모두 살펴볼 가치가 있다. 하지만 기존 도구가 해결해 주지 않는 필요가 있다면 직접 도구를 만드는 것도 생각해봐야 한다. 그것은 독립적인 도구일 수도 있고 기존 플랫폼 위에 구축된 것일 수도 있다.
로그를 나중에 추가할 인프라로 생각해서는 안된다. 로그가 없는 고통을 느낄 때가 되면, 가장 큰 도움이 되었을 로그는 이미 잃어버린 뒤다.
에이전트를 개선하기 위해 모델, 프롬프트, 도구를 바꿀 수 있다.
모델은 시스템 성능에서 가장 중요한 요소다. 더 좋은 모델은 평범한 프롬프트를 구제할 수 있지만, 나쁜 모델은 완벽한 프롬프트로도 구제할 수 없다. 새로운 모델은 계속해서 나온다. 핵심은 새 모델을 빠르게 테스트할 수 있어야 한다는 것이다. 모델을 교체하고, 평가를 실행하고, 점수를 비교한다. 평가가 잘 갖춰져 있다면 이 작업은 며칠이 아니라 몇십 분이 걸려야 한다. 모델 평가가 쉬워야 새 모델을 빠르게 적용할 수 있다.
프롬프트는 일상적인 개선이 일어나는 곳이다. 프롬프트를 개선하는 올바른 방법은 모델이 원하는 것을 상상하는 것이 아니라 로그를 읽는 것이다. 실패한 실행의 로그는 보통 모델이 무엇을 오해했는지, 프롬프트의 어떤 부분이 전달되지 않았는지 보여준다. 변경사항은 평가로 검증해야 한다. 어떤 실패를 고치는 프롬프트 변경이 다른 어떤 경우를 조용히 망가뜨릴 수 있다.
도구는 모델과 세상 사이의 인터페이스이며, 사용자 인터페이스처럼 주의 깊게 설계해야 한다. 설계의 목표는 올바른 사용을 쉽게 하고 잘못된 사용을 어렵게 만드는 것이다. 모델이 도구를 자주 잘못 사용한다면 -- 인자를 잘못된 형식으로 전달하거나, 잘못된 맥락에서 호출하거나, 출력을 오해한다면 -- 그것은 모델의 문제가 아니라 도구의 문제다. 사용자가 계속 같은 실수를 하면 사용자가 아니라 UI를 다시 설계하듯이, 모델이 의도하지 않은 행동을 계속하면 모델에 맞춰주는 것이 좋을 수 있다.
세 가지 모두 직관보다는 평가로 변경하는 것이 바람직하다. 무엇이 도움이 될지에 대한 직관은 자주 틀리지만, 평가 점수는 그렇지 않다.
언어 모델은 세상에 대한 방대한 지식을 가지고 있다. 프로그래밍 언어와 과학의 개념과 역사적 사실을 이해한다. 하지만 우리 조직과 코드베이스, 내부 도구, 해당 분야의 관습에 대해서는 잘 모른다. 모델의 잘못이 아니라 알려주지 않았기 때문이다.
실용적인 해결책은 모델에게 필요한 것을 주는 것이다. 정보 소스와 사용법을 제공해야 한다. 에이전트가 내부 데이터베이스를 질의해야 한다면, 그렇게 할 수 있는 CLI를 주고 사용법 문서도 같이 준다. 코드베이스 특유의 관습을 따라야 한다면, 그 관습을 파일에 적어 둔다. 지식 베이스를 참조해야 한다면, 검색 도구를 주고 스키마를 설명한다. 모델의 추론 능력보다 추론할 재료가 문제인 경우가 많다.
Anthropic은 이 패턴을 에이전트 스킬 [6]로 공식화했다. 스킬은 지침이 담긴 SKILL.md 파일과 지원 스크립트 및 리소스로 구성된 폴더다. 시작할 때 에이전트는 설치된 각 스킬의 이름과 설명만 미리 읽어둔다. 작업이 관련 스킬을 트리거하면, 에이전트는 전체 지침과 링크된 파일을 필요에 따라 읽는다. 이 점진적 공개 설계 덕분에 컨텍스트 윈도에는 한계가 있지만 스킬에는 그보다 많은 컨텍스트를 담을 수 있다.
Anthropic의 스킬 형식을 사용하지 않더라도, 아이디어는 일반적으로 적용할 수 있다.. 에이전트에게 필요하지만 일반 지식으로는 유추할 수 없는 컨텍스트가 무엇인지 파악하고, 그 컨텍스트를 발견 가능한 리소스로 패키징하고, 에이전트가 필요에 따라 접근할 수 있는 도구를 주어라.
새 모델과 큰 모델이 능사는 아니다. 프론티어 모델은 비싸고 느리다. 에이전트 시스템 내의 많은 작업은 더 작은 모델로 충분하다. 실용적인 접근법은 각 작업을 안정적으로 할 수 있는 가장 작은 모델을 사용하는 것이다. 여러 모델을 대상으로 평가를 실행해 변곡점을 찾고, 그보다 한 단계 위의 모델을 쓰면 된다.
출력 토큰은 입력 토큰보다 비싸다. 따라서 입력 토큰보다 출력 토큰을 아껴야 한다. 필요한 것만 요청해 출력을 최소화하라. 작업을 위해 무거운 처리 전에 분류나 필터링이 필요하다면, 가벼운 단계를 먼저 하라. 천 개의 항목을 분류해 깊게 분석할 가치 있는 스무 개를 찾는 것은 천 개 모두 전체 분석을 실행하는 것보다 훨씬 저렴하다. 그리고 분류 단계는 분석 단계보다 더 작은 모델을 쓸 수 있는 경우가 많다.
프롬프트 캐싱은 입력 비용을 줄이는 가장 효과적인 수단 중 하나다. OpenAI와 Anthropic 모두 반복되는 프롬프트 접두사를 캐싱하므로, 매 요청 앞에 등장하는 내용 -- 시스템 프롬프트와 도구 정의 -- 은 한 번 캐싱되면 이후 호출에서 훨씬 저렴해진다. 안정적인 내용을 컨텍스트 앞에 두고 호출 사이에 편집하지 마라. 컨텍스트 편집 -- 대화의 앞부분을 재배열하거나, 요약하거나, 다듬는 것 -- 은 캐시를 파괴하므로 신중하게 접근해야 한다.
해야할 일을 배치 작업으로 구조화할 수 있다면 -- 실시간 요건 없이 처리되는 많은 독립적 입력 -- OpenAI와 Anthropic 모두 상당한 할인율로 배치 API를 제공한다. 배치 처리는 대화형 에이전트에는 적합하지 않지만, 평가 실행, 대규모 분류 작업, 지연 시간 제약이 없는 워크로드에서 비용을 크게 줄일 수 있다.
멀티 에이전트 시스템은 단순히 병렬로 실행하는 방법이 아니다. 두 가지 목적이 있다. 적당한 크기로 작업을 분해하는 것, 그리고 희소하고 제한된 자원인 컨텍스트 윈도를 아끼는 것이다.
컨텍스트 윈도 제약을 과소평가하는 경우가 많다. 컨텍스트 윈도 안의 모든 것이 모델의 주의를 두고 경쟁한다. 모든 중간 결과, 모든 도구 응답, 탐색하다 막힌 모든 막다른 길. 하나의 에이전트가 큰 작업을 처리하면 이 모든 것이 한 곳에 쌓인다. 정작 중요한 부분에 다다를 때쯤이면, 이전 단계에서 나온 무관하거나 오히려 방해가 되는 자료들로 컨텍스트가 가득 차 있다. 별도의 에이전트는 각자 자신의 작업에만 관련된 깔끔하고 집중된 컨텍스트를 갖는다.
작업 분해가 또 다른 이유다. 하나의 에이전트가 잘 처리하기에 너무 큰 작업은 보통 상호 의존성이 적은 하위 작업으로 나눌 수 있다. 오케스트레이터의 역할은 그 구조를 파악하는 것이다. 어떤 부분이 독립적으로 진행될 수 있는지, 어떤 것이 순서를 지켜야 하는지, 어떤 결과를 마지막에 종합해야 하는지. 이것은 단순한 프롬프팅 문제가 아니라 설계의 문제이다.
멀티 에이전트 아키텍처가 항상 올바른 선택은 아니다. 작업이 본질적으로 순차적이라면 -- 각 단계에서 이전의 모든 것에 대한 완전한 지식이 필요하다면 -- 에이전트를 분리해도 얻을 것이 거의 없고 문제점만 많아진다. 넓은 작업, 즉 병렬로 진행되다가 마지막에 종합하는 작업이 잘 맞는다. 단계 간 상호 의존성이 강한 촘촘하게 결합된 작업은 그렇지 않다.
멀티 에이전트 시스템은 비싸다. Anthropic에 따르면 멀티 에이전트 연구 시스템은 표준 채팅보다 약 15배 많은 토큰을 사용했다 [7]. 작업이 충분히 복잡하고 출력이 가치 있을 때만 그러한 비용이 정당화될 수 있다. 단일 에이전트로 처리할 수 있는 작업을 멀티 에이전트 시스템으로 하는 것은 낭비일 뿐이다.
서브에이전트는 오케스트레이터가 특정 하위 작업을 처리하기 위해 생성하는 에이전트이다. 별도의 컨텍스트 윈도와 도구, 실행 루프를 갖는다. 오케스트레이터는 작업을 위임하고, 결과를 기다리고, 그 결과를 자신의 컨텍스트에 통합한다.
서브에이전트에는 명확한 종료 조건이 필요하다. 완료되었음을 알리고 오케스트레이터가 사용할 수 있는 결과를 내놓는 무언가가 있어야 한다. 가장 깔끔한 메커니즘은 전용 출력 도구다. 모델이 출력 도구를 호출하면 실행이 끝나고 결과가 반환된다. 이것은 서브에이전트의 마지막 응답을 출력으로 사용하는 것보다 낫다. 명시적이고, 구조화되어 있고, 파싱하기 쉽기 때문이다.
Armin Ronacher는 모델이 출력 도구를 호출하지 못하는 경우가 있다고 지적한다 [8]. 이것은 실제 문제지만 해결할 수 없는 문제는 아니다. OpenAI와 Anthropic API 모두 특정 도구를 강제로 호출하게 할 수 있는 tool_choice 파라미터를 지원한다. 서브에이전트 실행이 끝날 때 작업을 마친 후 tool_choice를 출력 도구로 설정해 마지막 API 호출을 할 수 있다. 이렇게 하면 모델이 스스로 출력 도구를 호출하지 않으려 하더라도 구조화된 출력을 내도록 강제할 수 있다.
더 까다로운 문제는 실패다. 서브에이전트는 실패할 수 있으며, 가장 큰 피해를 주는 실패 방식은 명확한 오류가 아니라 진전 없이 길게 이어지는 실행이다. 문제가 되는 것은 오류의 증폭이다. 모델이 도구 결과를 잘못 읽고, 잘못된 방향으로 나아가고, 이후의 각 단계가 그 잘못된 기반 위에 쌓인다. 이런 실행은 턴 수 측면에서 가장 긴 경향이 있다. 성공할 서브에이전트는 대개 예측 가능한 턴 수 안에 성공한다. 그 지점을 넘어서도 계속 가는 것은 대개 막힌 것이다.
실용적인 해결책은 턴수 제한이다. 턴수 제한은 에이전트를 여러 작업에 실행해보고 성공적인 실행이 어디서 끝나는지 관찰해서 경험적으로 결정한다. 제한에 도달하면, 실행을 계속하게 두는 대신 포기하고 다시 시도한다. 깔끔한 컨텍스트로 새로 시작하면 길게 늘어진 실행이 실패할 곳에서 성공하는 경우가 많다. 이것은 에이전트가 점진적으로 진전을 이루고 있다고 생각한다면 직관에 반하지만, 오류 증폭은 막힌 에이전트가 나아지는 것이 아니라 종종 나빠지고 있음을 의미한다.
턴수 제한은 개발 중에 유용하기도 하다. 에이전트가 일상적으로 제한에 도달한다면, 그것은 작업 분해가 손질이 필요하다는 신호이거나, 도구가 모델에게 필요한 것을 주지 않고 있거나, 프롬프트가 언제 작업이 완료되었는지 충분히 명확하지 않다는 신호이다.
에이전트가 도구로 복잡한 작업을 해야 할 때 -- 여러 도구를 순서대로 호출하거나, 큰 결과를 필터링하거나, 항목 목록을 반복 처리하는 것 -- 단순한 접근법은 모델이 도구를 하나씩 호출하고, 호출 사이마다 모델을 거치는 것이다. 이것은 작동하지만 비싸고 느리다. 더 나은 방법이 있다. 모델에게 그 모든 것을 하는 코드를 생성하게 한 다음 코드를 실행하는 것이다.
이것이 가능한 이유는 언어 모델이 코드 생성에 유독 뛰어나기 때문이다. 언어 모델은 훈련에서 도구 호출보다 훨씬 많은 실제 코드를 보았다. 도구를 프로그래밍 언어의 호출 가능한 함수로 제시하면, 모델은 프로그래머가 그러듯이 반복문, 조건문, 오류 처리에 대해 추론할 수 있다. Cloudflare는 Code Mode [9]에서 명시적으로 그렇게 주장한다. 도구 호출은 모델이 드물게 접하는 패턴에 의존하지만, 코드 생성은 모델이 깊이 내면화한 패턴에 의존한다.
코드 생성의 토큰 절약 효과는 크다. 전통적인 도구 호출 루프에서는 모든 중간 결과가 모델의 컨텍스트 윈도를 거친다. 2시간짜리 회의 녹취를 가져와 CRM에 첨부하면, 전체 녹취가 컨텍스트에 두 번 들어간다. 20명 직원의 예산 데이터를 하나씩 조회하면, 요약하기 전에 20개의 응답이 모두 컨텍스트에 적재된다. 코드 생성을 사용하면 중간 결과가 실행 환경에 머물고, 최종 출력 -- 필터링된 요약, 합계 -- 만 모델에게 돌아간다. Anthropic은 대표적인 사례에서 토큰 사용량을 15만에서 2천으로 줄였다고 보고한다 [10].
실용적인 구현에는 세 가지가 필요하다.
코드 실행 환경. 생성된 코드가 어딘가에서 실행되어야 한다. 샌드박스가 필요하다. 네트워크 접근을 제한하고, 의도한 것 이외의 파일시스템 접근을 금지해야 한다. Cloudflare는 V8 isolate를 사용하고, Anthropic은 Python 컨테이너를 사용한다. 직접 구축한다면 인프라가 간단하지는 않지만, 샌드박스는 일반적으로 사용할 수 있다.
함수로 노출된 도구. 모델은 어떤 함수가 사용 가능하고 무엇을 반환하는지 알아야 한다. 출력 형식에 대한 설명이 중요하다. 도구가 JSON을 반환한다면 스키마를 설명하라. 모델이 코드를 작성하려면 기대해야 하는 결과를 알아야 한다.
도구별 옵트인. 모든 도구가 생성된 코드에서 호출 가능해야 하는 것은 아니다. Anthropic의 API는 각 도구 정의의 allowed_callers 필드로 이를 구현한다 [11]. 모델이 직접 호출하는 도구와 코드에서 호출하는 도구를 구분한다. 이 구분은 보안상 중요하다. 부작용이 있거나 민감한 출력을 가진 도구는 두 맥락에서 다른 처리가 필요할 수 있다.
도구 사용 외에도 같은 원칙이 적용된다. 에이전트가 데이터를 처리해야 할 때 -- 파일을 변환하거나, 질의 결과를 집계하거나, 목록을 필터링하는 -- 코드를 작성하게 하고 그 코드를 실행하는 것이 자연어로 데이터에 대해 추론하게 하는 것보다 나은 경우가 많다. 모델의 코드 생성 능력은 코딩 에이전트만을 위한 기능이 아니라 기본적인 도구이다.
이 패턴을 채택하고 싶다면, MCPorter [12]가 도움이 될 수 있다. MCPorter는 MCP 서버의 도구 정의에서 TypeScript 래퍼를 생성하는 오픈 소스 TypeScript 라이브러리이다.
한 가지 주의사항이 있다. 이 패턴은 실행 환경이 진정으로 격리되어 있어야 한다. 생성된 코드는 신뢰할 수 없는 입력이다. 에이전트가 악의적인 코드를 생성하게 하는 프롬프트로 공격당할 수 있다. 샌드박싱은 선택사항이 아니다.
에이전트가 기계가 읽을 수 있는 출력을 내놓아야 할 때는 -- 분류, 결정, 필드 추출 -- 구조화된 출력이 올바른 도구다. 텍스트를 파싱하는 대신, 스키마를 정의하고 모델이 채운다. 더 신뢰할 수 있고, 테스트하기 더 쉽고, 파싱 버그를 통째로 제거한다.
언어 모델은 토큰을 왼쪽에서 오른쪽으로 순서대로 생성한다. 스키마를 {"answer": "..."} 로 정의하면, 모델은 바로 답을 정한다. {"reasoning": "...", "answer": "..."} 로 정의하면, 모델은 먼저 추론하도록 강제되고 그 추론이 답에 영향을 미친다. 추론 필드가 스키마에서 답 필드보다 앞에 오므로, 출력에서도 답 앞에 온다.
나중에 추론을 완전히 버리고 답만 사용해도 된다. 성능상의 이점은 추론을 읽는 것이 아니라 모델이 추론을 생성했다는 데서 온다. 이 방법은 특별한 모델 지원 없이 추론 모델과 같은 효과를 얻을 수 있게 해 준다.
에이전트가 파일을 수정해야 한다면 파일 편집을 어떻게 구현하느냐가 시스템 성능에 중요한 영향을 미친다.
이것은 내 경험만이 아니다. Anthropic은 파일 편집 신뢰성을 명시적으로 어려운 문제 중 하나로 꼽았다 [13]. Anthropic이 API로 제공하는 텍스트 편집기 도구 [14]를 보면, str_replace 명령은 정확한 문자열 일치를 필요로 하며, 하니스는 문자열이 일치하지 않거나 여러 번 일치할 때 오류를 반환해야 한다. 문제가 충분히 어렵기 때문에 Anthropic은 도구 설계에 우회책을 내장했다 (예를 들어 파일의 절대 경로를 요구하는 것은 명시적인 오류 방지 조치다).
어려운 점은 모델이 원하는 변경에 대해 추론할 뿐 아니라, 모호함이나 오류 없이 파일에 기계적으로 적용할 수 있는 형식으로 출력을 내놓아야 한다는 것이다. 이것은 서로 다른 일이며, 어떤 형식을 선택하느냐에 따라 기계적인 적용 단계가 얼마나 자주 실패하는지가 달라진다.
현재 사용되는 주요 접근법은 다음과 같다.
전체 파일 재작성. 모델이 파일의 내용을 완전히 새로 출력한다. 구현하고 파싱하기 단순하며, 형식 오류로 실패하지 않는다. 단점은 비용(출력 토큰이 파일 크기에 비례해 증가함)과 주변 컨텍스트 손실이다. 작은 파일에서만 실용적이다.
문자열 교체. 모델이 이전 문자열과 새 문자열을 출력하면, 하니스가 찾아서 교체한다. Anthropic이 사용하는 방식이다 [14]. 실패 방식은 잘 알려져 있다. 모델은 공백과 들여쓰기를 포함해 이전 문자열을 글자 하나 하나 그대로 재현해야 하는데, 이것을 자주 틀린다. "교체할 문자열을 찾지 못했다"는 오류는 에이전트 실패의 흔한 원인이다.
patch/diff 형식. 모델이 변경사항을 설명하는 구조화된 diff를 출력한다. OpenAI의 Codex는 *** Begin Patch 와 *** End Patch 마커가 있는 커스텀 패치 형식을 사용한다. 그 자체로는 쉽게 망가지지만 Codex는 제약된 샘플링(constrained sampling)으로 이를 해결한다. 패치 형식을 Lark 문맥 자유 문법(context free grammar)으로 표현하고, 추론 시 모델 출력을 문법에 맞게 제한한다 [15]. 이것은 형식 오류를 통째로 제거한다. 이것이 OpenAI의 공개 API를 사용해 이루어진다는 점이 중요하다 [16]. 이 기법은 누구나 사용할 수 있다.
훈련된 병합 모델. Cursor는 모델의 편집 의도를 원본 파일과 병합하는 별도의 70B 모델을 훈련했다. 병합 견고성을 학습된 능력으로 만들어 형식 문제를 완전히 우회한다. 명백한 비용은 전용 모델을 훈련하고 서빙하는 데 상당한 자원이 필요하다는 것이다.
Can Bölük은 16개 모델을 180개 과제에서 벤치마킹하여 형식 선택만으로도 성공률이 달라질 수 있음을 보였다 [17]. 그의 글은 이 장과 함께 읽을 가치가 있다. 그가 제안한 형식은 각 줄에 줄 번호와 짧은 해시를 태그한다. 주요 이점은 모델이 정확한 내용을 재현하지 않고 식별자로 줄을 참조할 수 있다는 것인데, 이것이 모델에게는 훨씬 쉽다. 해시는 줄 번호에 더해서 체크섬 역할을 한다. 이전 편집으로 줄이 밀렸다면, 예상 해시와 실제 줄 내용 사이의 불일치가 잘못된 줄을 조용히 편집하는 대신 오류를 잡아낸다.
에이전트에게 도구를 준다는 것은 세상에서 실제 행동을 취할 수 있는 능력을 주는 것이다 -- 파일 읽기, 파일 쓰기, 명령 실행, 외부 서비스 호출. 도구 인가 제어는 에이전트가 자율적으로 취할 수 있는 행동과 사람의 승인이 필요한 행동을 결정하는 방법이다. 이것을 제대로 하는 것은 안전과 사용성 모두에 중요하다. 너무 제한적이면 에이전트가 일을 할 수 없고, 너무 허용적이면 모르는 사이에 피해를 줄 수 있는 자율 시스템이 된다.
먼저 이해해야 할 것은 인가와 샌드박싱이 상호 보완적이며 서로 대체할 수 없다는 것이다. 인가는 에이전트가 무엇을 하기로 결정하는지를 제어하며 에이전트 수준에서 작동한다. 샌드박싱은 에이전트가 무엇을 결정하든 관계없이 OS 수준에서 제한을 강제한다. Claude Code의 문서 [18]는 이 구분을 명확히 한다. 인가는 에이전트가 제한된 행동을 시도하는 것을 막고, 샌드박싱은 에이전트가 제한된 행동을 시도하더라도 그러한 행동이 실제로 실행되는 것을 막는다. 둘 다 사용해야 한다.
덜 명백한 점은 Bash 인가 규칙이 보이는 것보다 강한 점도 있고 약한 점도 있다는 것이다.
보이는 것보다 강한 이유는 셸 명령이 문자열로만 매칭되지 않고 파싱되기 때문이다. Claude Code는 오픈 소스가 아니지만, Bun을 사용한다고 알려져 있는데, Bun에는 셸 파서가 포함되어 있다. Codex(오픈 소스)는 Tree-sitter의 Bash 파서로 같은 작업을 한다 [19]. 스크립트가 완전한 AST로 파싱되고, 단순한 명령 이외의 것이 포함되면 파싱이 거부된다. 허용된 연산자 (&&, ||, ;, |)는 각 개별 명령을 추출하고 각각을 인가 규칙과 별도로 확인하는 방식으로 처리된다. 즉 Bash(safe-cmd *)는 safe-cmd && malicious-cmd를 허용하지 않는다. 파서가 두 개의 명령을 보고 둘 다 확인한다.
보이는 것보다 약한 이유는 명령 이름 수준에서 안전성을 알 수 없기 때문이다. 고전적인 예시가 있다. rm을 거부하고 find를 허용해도 파일 삭제가 막히지 않는다. find에는 -delete 옵션이 있기 때문이다. 많은 유닉스 명령이 이처럼 다목적이다. 특정 명령이 안전하다는 가정 하에 작성된 단순한 허용 목록은 이러한 구멍이 생기는 경향이 있으며, 에이전트나 프롬프트 인젝션을 통해 에이전트를 제어하는 공격자는 그러한 구멍을 찾아낼 수 있다.
코딩 에이전트를 위한 실용적인 인가 모델은 이런 모습일 수 있다. 읽기 작업은 승인이 필요 없다. 파일 편집은 세션당 한 번 승인이 필요하다. 셸 명령은 명령당 승인이 필요하되, 테스트 실행이나 프로젝트 빌드 같은 일반적이고 안전한 작업은 미리 승인된 허용 목록에 넣는다.
파일이나 웹를 읽는 에이전트는 그 내용으로부터 공격자의 지시를 받을 수 있다. 엄격한 인가 규칙이 주요 방어책이다. 데이터를 유출하라는 지시는 에이전트가 외부 URL에 도달할 수 없다면 성공할 수 없다.
[1] Takeshi Kojima et al., "Large Language Models are Zero-Shot Reasoners", 2022-05-24. https://arxiv.org/abs/2205.11916
[2] Lennart Meincke et al., "Prompting Science Report 2: The Decreasing Value of Chain of Thought in Prompting", 2025-06-08. https://arxiv.org/abs/2506.07142
[3] OpenAI, "Why SWE-bench Verified no longer measures frontier coding capabilities", 2026-02-23. https://openai.com/index/why-we-no-longer-evaluate-swe-bench-verified/
[4] Langfuse. https://langfuse.com/
[5] Pydantic Logfire. https://pydantic.dev/logfire
[6] Agent Skills. https://agentskills.io/
[7] Anthropic, "How we built our multi-agent research system", 2025-06-13. https://www.anthropic.com/engineering/multi-agent-research-system
[8] Armin Ronacher, "Agent Design Is Still Hard", 2025-11-21. https://lucumr.pocoo.org/2025/11/21/agents-are-hard/
[9] Cloudflare, "Code Mode: the better way to use MCP", 2025-09-26. https://blog.cloudflare.com/code-mode/
[10] Anthropic, "Code execution with MCP: Building more efficient agents", 2025-11-04. https://www.anthropic.com/engineering/code-execution-with-mcp
[11] Anthropic, "Programmatic tool calling". https://platform.claude.com/docs/en/agents-and-tools/tool-use/programmatic-tool-calling
[12] Peter Steinberger, MCPorter. https://github.com/steipete/mcporter
[13] Anthropic, "Raising the bar on SWE-bench Verified with Claude 3.5 Sonnet", 2025-01-06. https://www.anthropic.com/engineering/swe-bench-sonnet
[14] Anthropic, "Text editor tool". https://platform.claude.com/docs/en/agents-and-tools/tool-use/text-editor-tool
[15] OpenAI, codex-rs/core/src/tools/handlers/apply_patch.rs, tool_apply_patch.lark. https://github.com/openai/codex
[16] OpenAI, "Function calling". https://developers.openai.com/api/docs/guides/function-calling
[17] Can Bölük, "I Improved 15 LLMs at Coding in One Afternoon. Only the Harness Changed.", 2026-02-12. https://blog.can.ac/2026/02/12/the-harness-problem/
[18] Anthropic, "Configure permissions". https://code.claude.com/docs/en/permissions
[19] OpenAI, codex-rs/shell-command/src/bash.rs. https://github.com/openai/codex
I've been increasingly concerned about the corporate monopoly over frontier LLMs. While many ethically-minded people choose to boycott these models, I believe passive resistance alone cannot break the structural grip of big tech. To truly “liberate” these technologies and turn them into public goods, we need to look beyond moral high grounds and engage with the material basis of AI—specifically compute, data, and the relations of production.
I've written two posts exploring this through the lens of historical materialism. The first piece analyzes why current “open source” definitions struggle with LLMs, and the second discusses what it means to “act materialistically” in our imperfect world. My goal is to suggest a path forward that moves from mere boycotting to a more proactive, structural socialization of AI infrastructure.
If you've been feeling uneasy about the AI landscape but aren't sure if boycotting is the final answer, I'd love for you to give these a read:
#LLM #AI #opensource #historicalmaterialism #histomat #materialism #digitalcommons
I've been increasingly concerned about the corporate monopoly over frontier LLMs. While many ethically-minded people choose to boycott these models, I believe passive resistance alone cannot break the structural grip of big tech. To truly “liberate” these technologies and turn them into public goods, we need to look beyond moral high grounds and engage with the material basis of AI—specifically compute, data, and the relations of production.
I've written two posts exploring this through the lens of historical materialism. The first piece analyzes why current “open source” definitions struggle with LLMs, and the second discusses what it means to “act materialistically” in our imperfect world. My goal is to suggest a path forward that moves from mere boycotting to a more proactive, structural socialization of AI infrastructure.
If you've been feeling uneasy about the AI landscape but aren't sure if boycotting is the final answer, I'd love for you to give these a read:
#LLM #AI #opensource #historicalmaterialism #histomat #materialism #digitalcommons
I've been increasingly concerned about the corporate monopoly over frontier LLMs. While many ethically-minded people choose to boycott these models, I believe passive resistance alone cannot break the structural grip of big tech. To truly “liberate” these technologies and turn them into public goods, we need to look beyond moral high grounds and engage with the material basis of AI—specifically compute, data, and the relations of production.
I've written two posts exploring this through the lens of historical materialism. The first piece analyzes why current “open source” definitions struggle with LLMs, and the second discusses what it means to “act materialistically” in our imperfect world. My goal is to suggest a path forward that moves from mere boycotting to a more proactive, structural socialization of AI infrastructure.
If you've been feeling uneasy about the AI landscape but aren't sure if boycotting is the final answer, I'd love for you to give these a read:
#LLM #AI #opensource #historicalmaterialism #histomat #materialism #digitalcommons
I've been increasingly concerned about the corporate monopoly over frontier LLMs. While many ethically-minded people choose to boycott these models, I believe passive resistance alone cannot break the structural grip of big tech. To truly “liberate” these technologies and turn them into public goods, we need to look beyond moral high grounds and engage with the material basis of AI—specifically compute, data, and the relations of production.
I've written two posts exploring this through the lens of historical materialism. The first piece analyzes why current “open source” definitions struggle with LLMs, and the second discusses what it means to “act materialistically” in our imperfect world. My goal is to suggest a path forward that moves from mere boycotting to a more proactive, structural socialization of AI infrastructure.
If you've been feeling uneasy about the AI landscape but aren't sure if boycotting is the final answer, I'd love for you to give these a read:
#LLM #AI #opensource #historicalmaterialism #histomat #materialism #digitalcommons
I've been increasingly concerned about the corporate monopoly over frontier LLMs. While many ethically-minded people choose to boycott these models, I believe passive resistance alone cannot break the structural grip of big tech. To truly “liberate” these technologies and turn them into public goods, we need to look beyond moral high grounds and engage with the material basis of AI—specifically compute, data, and the relations of production.
I've written two posts exploring this through the lens of historical materialism. The first piece analyzes why current “open source” definitions struggle with LLMs, and the second discusses what it means to “act materialistically” in our imperfect world. My goal is to suggest a path forward that moves from mere boycotting to a more proactive, structural socialization of AI infrastructure.
If you've been feeling uneasy about the AI landscape but aren't sure if boycotting is the final answer, I'd love for you to give these a read:
#LLM #AI #opensource #historicalmaterialism #histomat #materialism #digitalcommons
I've been increasingly concerned about the corporate monopoly over frontier LLMs. While many ethically-minded people choose to boycott these models, I believe passive resistance alone cannot break the structural grip of big tech. To truly “liberate” these technologies and turn them into public goods, we need to look beyond moral high grounds and engage with the material basis of AI—specifically compute, data, and the relations of production.
I've written two posts exploring this through the lens of historical materialism. The first piece analyzes why current “open source” definitions struggle with LLMs, and the second discusses what it means to “act materialistically” in our imperfect world. My goal is to suggest a path forward that moves from mere boycotting to a more proactive, structural socialization of AI infrastructure.
If you've been feeling uneasy about the AI landscape but aren't sure if boycotting is the final answer, I'd love for you to give these a read:
#LLM #AI #opensource #historicalmaterialism #histomat #materialism #digitalcommons
I've been increasingly concerned about the corporate monopoly over frontier LLMs. While many ethically-minded people choose to boycott these models, I believe passive resistance alone cannot break the structural grip of big tech. To truly “liberate” these technologies and turn them into public goods, we need to look beyond moral high grounds and engage with the material basis of AI—specifically compute, data, and the relations of production.
I've written two posts exploring this through the lens of historical materialism. The first piece analyzes why current “open source” definitions struggle with LLMs, and the second discusses what it means to “act materialistically” in our imperfect world. My goal is to suggest a path forward that moves from mere boycotting to a more proactive, structural socialization of AI infrastructure.
If you've been feeling uneasy about the AI landscape but aren't sure if boycotting is the final answer, I'd love for you to give these a read:
#LLM #AI #opensource #historicalmaterialism #histomat #materialism #digitalcommons
I've been increasingly concerned about the corporate monopoly over frontier LLMs. While many ethically-minded people choose to boycott these models, I believe passive resistance alone cannot break the structural grip of big tech. To truly “liberate” these technologies and turn them into public goods, we need to look beyond moral high grounds and engage with the material basis of AI—specifically compute, data, and the relations of production.
I've written two posts exploring this through the lens of historical materialism. The first piece analyzes why current “open source” definitions struggle with LLMs, and the second discusses what it means to “act materialistically” in our imperfect world. My goal is to suggest a path forward that moves from mere boycotting to a more proactive, structural socialization of AI infrastructure.
If you've been feeling uneasy about the AI landscape but aren't sure if boycotting is the final answer, I'd love for you to give these a read:
#LLM #AI #opensource #historicalmaterialism #histomat #materialism #digitalcommons
I've been increasingly concerned about the corporate monopoly over frontier LLMs. While many ethically-minded people choose to boycott these models, I believe passive resistance alone cannot break the structural grip of big tech. To truly “liberate” these technologies and turn them into public goods, we need to look beyond moral high grounds and engage with the material basis of AI—specifically compute, data, and the relations of production.
I've written two posts exploring this through the lens of historical materialism. The first piece analyzes why current “open source” definitions struggle with LLMs, and the second discusses what it means to “act materialistically” in our imperfect world. My goal is to suggest a path forward that moves from mere boycotting to a more proactive, structural socialization of AI infrastructure.
If you've been feeling uneasy about the AI landscape but aren't sure if boycotting is the final answer, I'd love for you to give these a read:
#LLM #AI #opensource #historicalmaterialism #histomat #materialism #digitalcommons
I've been increasingly concerned about the corporate monopoly over frontier LLMs. While many ethically-minded people choose to boycott these models, I believe passive resistance alone cannot break the structural grip of big tech. To truly “liberate” these technologies and turn them into public goods, we need to look beyond moral high grounds and engage with the material basis of AI—specifically compute, data, and the relations of production.
I've written two posts exploring this through the lens of historical materialism. The first piece analyzes why current “open source” definitions struggle with LLMs, and the second discusses what it means to “act materialistically” in our imperfect world. My goal is to suggest a path forward that moves from mere boycotting to a more proactive, structural socialization of AI infrastructure.
If you've been feeling uneasy about the AI landscape but aren't sure if boycotting is the final answer, I'd love for you to give these a read:
#LLM #AI #opensource #historicalmaterialism #histomat #materialism #digitalcommons
I've been increasingly concerned about the corporate monopoly over frontier LLMs. While many ethically-minded people choose to boycott these models, I believe passive resistance alone cannot break the structural grip of big tech. To truly “liberate” these technologies and turn them into public goods, we need to look beyond moral high grounds and engage with the material basis of AI—specifically compute, data, and the relations of production.
I've written two posts exploring this through the lens of historical materialism. The first piece analyzes why current “open source” definitions struggle with LLMs, and the second discusses what it means to “act materialistically” in our imperfect world. My goal is to suggest a path forward that moves from mere boycotting to a more proactive, structural socialization of AI infrastructure.
If you've been feeling uneasy about the AI landscape but aren't sure if boycotting is the final answer, I'd love for you to give these a read:
#LLM #AI #opensource #historicalmaterialism #histomat #materialism #digitalcommons
I've been increasingly concerned about the corporate monopoly over frontier LLMs. While many ethically-minded people choose to boycott these models, I believe passive resistance alone cannot break the structural grip of big tech. To truly “liberate” these technologies and turn them into public goods, we need to look beyond moral high grounds and engage with the material basis of AI—specifically compute, data, and the relations of production.
I've written two posts exploring this through the lens of historical materialism. The first piece analyzes why current “open source” definitions struggle with LLMs, and the second discusses what it means to “act materialistically” in our imperfect world. My goal is to suggest a path forward that moves from mere boycotting to a more proactive, structural socialization of AI infrastructure.
If you've been feeling uneasy about the AI landscape but aren't sure if boycotting is the final answer, I'd love for you to give these a read:
#LLM #AI #opensource #historicalmaterialism #histomat #materialism #digitalcommons
I've been increasingly concerned about the corporate monopoly over frontier LLMs. While many ethically-minded people choose to boycott these models, I believe passive resistance alone cannot break the structural grip of big tech. To truly “liberate” these technologies and turn them into public goods, we need to look beyond moral high grounds and engage with the material basis of AI—specifically compute, data, and the relations of production.
I've written two posts exploring this through the lens of historical materialism. The first piece analyzes why current “open source” definitions struggle with LLMs, and the second discusses what it means to “act materialistically” in our imperfect world. My goal is to suggest a path forward that moves from mere boycotting to a more proactive, structural socialization of AI infrastructure.
If you've been feeling uneasy about the AI landscape but aren't sure if boycotting is the final answer, I'd love for you to give these a read:
#LLM #AI #opensource #historicalmaterialism #histomat #materialism #digitalcommons
I've been increasingly concerned about the corporate monopoly over frontier LLMs. While many ethically-minded people choose to boycott these models, I believe passive resistance alone cannot break the structural grip of big tech. To truly “liberate” these technologies and turn them into public goods, we need to look beyond moral high grounds and engage with the material basis of AI—specifically compute, data, and the relations of production.
I've written two posts exploring this through the lens of historical materialism. The first piece analyzes why current “open source” definitions struggle with LLMs, and the second discusses what it means to “act materialistically” in our imperfect world. My goal is to suggest a path forward that moves from mere boycotting to a more proactive, structural socialization of AI infrastructure.
If you've been feeling uneasy about the AI landscape but aren't sure if boycotting is the final answer, I'd love for you to give these a read:
#LLM #AI #opensource #historicalmaterialism #histomat #materialism #digitalcommons
Looking for a #git hosting that is against #AI and does not promote this #shit.
Criteria: reliability, long-term sustainability, financial independence.
A paid service, but without it being a hold-up.
RT welcome.
Links & Benchmarks also welcome.
Thanks !
@[email protected] · Reply to Simon Willison's post
@simon Fascinating framing! The "Claw" terminology feels right - these agent systems need a name that distinguishes them from chat-based AI. The messaging protocol angle is key: agents that can discover and pay for services autonomously (like x402 micropayments) could be the next layer.
While hoping and waiting for the bubble to pop, I have started writing about the planet-burning brain asbestos of our times, starting with issues related to sovereignty, independence and dependency on unsavory companies.
https://blog.mathieui.net/ai-and-sovereignty.html
This is a split from a mega-post that I have started writing more than a year ago and that I can’t seem to finish ever, so apologies if it does not reach a real conclusion on its own 🫠.
#ai #blog #blogging
#KI #AI (€) "Gedrucktes, das notwendigerweise aus dem Schreiben hervorgeht, ist gleichbedeutend mit #Demokratie: Erfinde das Schreiben und Demokratie ist unvermeidlich.
In der Gegenwart verlieren menschliches Denken und Schreiben offenbar an Bedeutung. Angesichts von #fakenews und Künstlicher Intelligenz, die auf die gleiche Frage immer andere Antworten gibt, kann man längst nicht mehr sicher sein, dass die Wahrheit im Licht der Öffentlichkeit wirklich ans Licht kommt."
https://www.spiegel.de/geschichte/medienrevolutionen-und-oeffentlichkeit-erfinde-das-schreiben-und-demokratie-ist-unvermeidlich-a-645107fc-b156-4f80-bc3a-1ac3a2ed3459
Ocassionally some silly silly folk will call me a #broligarch fanboi (or the newly coined #Aibooster) "thinking" I'm 100% in support of #AI and block me merely for debating, rather than echoing the #Luddite chorus.
... I drew this cartoon 35 years ago (1991 - Hal '91)
Long before all the wannabe kool kids were #antiai
Point is, I did not arrive at my AI position overnight (#regulateAI), as most folk had. I had a few dacades to mull things over.
Can you spot the #Dilbert influence?
I was always in the bleeding edge of #zeitgeist , Dilbert was only 3 years old.
#cartoon


RE: https://mstdn.feddit.social/@admin/115785498204274814
本来以为自己足够跟上了时代,但是发现自己其实还停留在2023时代AI对话的模式
每天用AI,虽然gpt gemini deepseek grok都会用但是还是太死板不敢尝试其他AI产品...
这个闪卡功能真的好棒,真的真的对于学习来说很有帮助,继续探索还有什么功能...
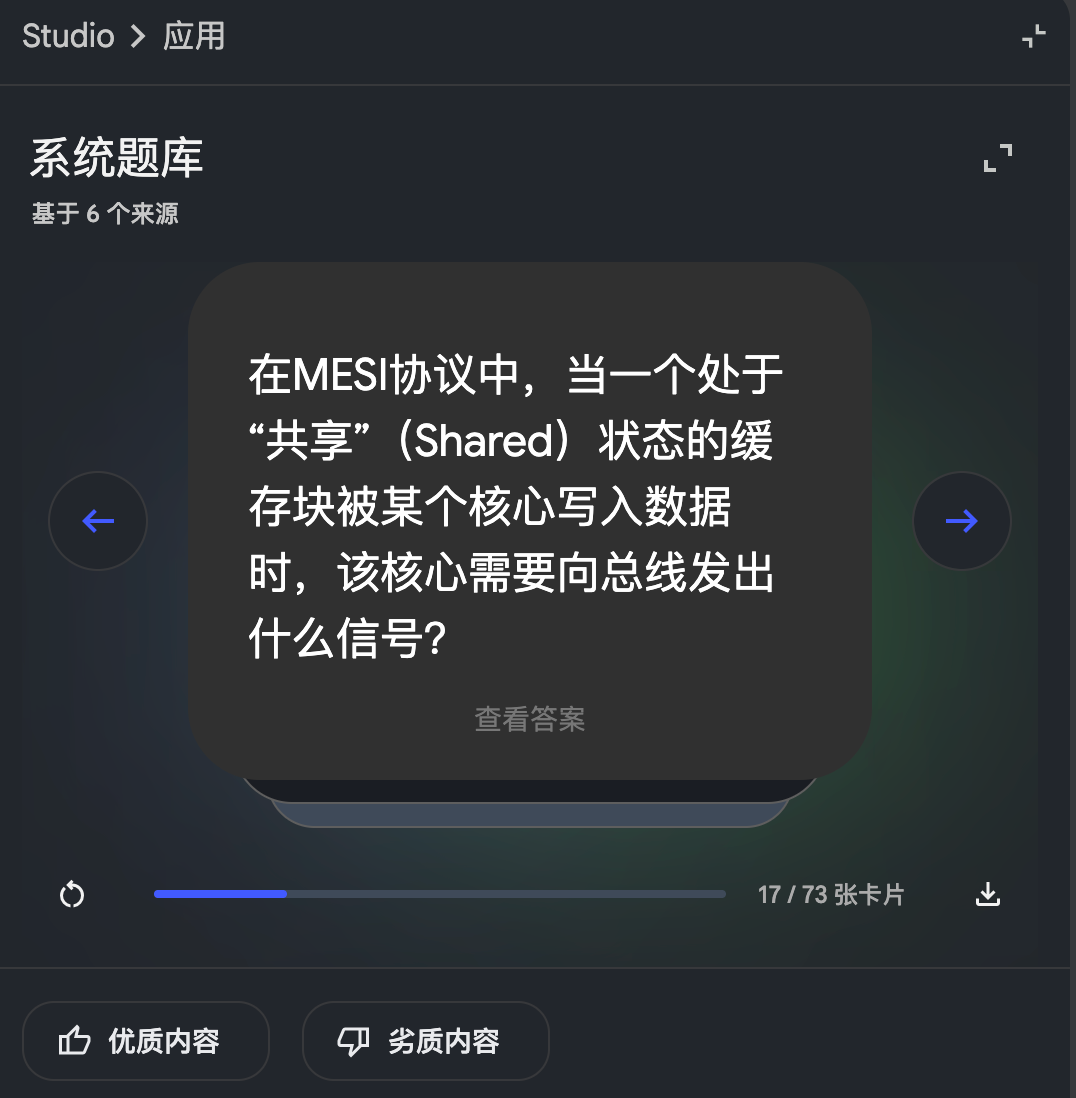
RE: https://mstdn.feddit.social/@admin/115785452273903367
Linux Kernel Compilation and DHCP Server Configuration Laboratory
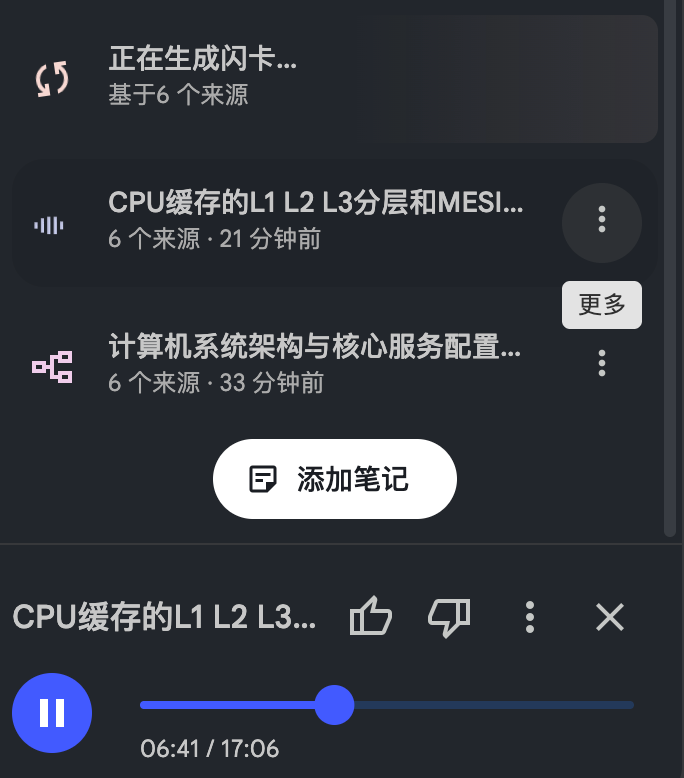
生成了一个音频,但是好像主要讲的是CPU
CPU缓存的L1 L2 L3分层和MESI协议:https://notebooklm.google.com/notebook/599b2e98-9d43-4c10-bd48-081bc55560fa?artifactId=bc56f351-fe79-4dcf-b967-6342da67423c
原来网上的访谈对话是这么生成的2333,不需要我调试自己就生成了
NotebookLM把我的博客网站扒了个精光,现在我要去霍霍其他博客了
“It should be clear to everyone (but for those that profit otherwise) how #ai can be an opportunity if we keep our hands on the wheel, or a problem if we let it drive to wherever the owners of each road want to take us.” https://blog.viewfromtheweb.com/the-ai-doom-under-our-control-43352b34/ 👈 On the AI doom under our control ✊

@[email protected] · Reply to Paolo Melchiorre's post
@simon you were one of the first in our community to seriously explore this space, through many concrete experiments and write-ups, including the recent post about migrating JustHTML from Python to JavaScript.
I don’t know if you get to read all notifications and mentions here on Mastodon, but if you have any thoughts on how to handle AI-generated contributions in large Open Source projects like Django, they would really help this discussion. 😃
@[email protected] · Reply to Benjamin Balder Bach's post
Thanks for the link @benjaoming ,I didn’t know that Python.org page and it’s very useful. Django has a similar section for AI-assisted security reports:
https://docs.djangoproject.com/en/dev/internals/security/#ai-assisted-reports
What I find interesting is how GNOME, Python, and Django converge on the same idea: AI can be a tool, but responsibility, disclosure, and reviewability stay with the contributor, otherwise the cost shifts to maintainers.
Maybe the next step is finding a shared place to collect and compare these approaches.
@[email protected] · Reply to Paolo Melchiorre's post
Continuing to listen to @djangochat , the topic of AI-generated contributions came up. 🎧
Shortly after, I read a post from the GNOME Extensions team explaining why they had to add a new review rule. They are seeing more and more patches generated with AI, full of unnecessary code, bad patterns, and little real understanding behind them. 🤖
https://blogs.gnome.org/jrahmatzadeh/2025/12/06/ai-and-gnome-shell-extensions/
It feels like a shared Open Source problem. Have you seen similar issues elsewhere? 🐛
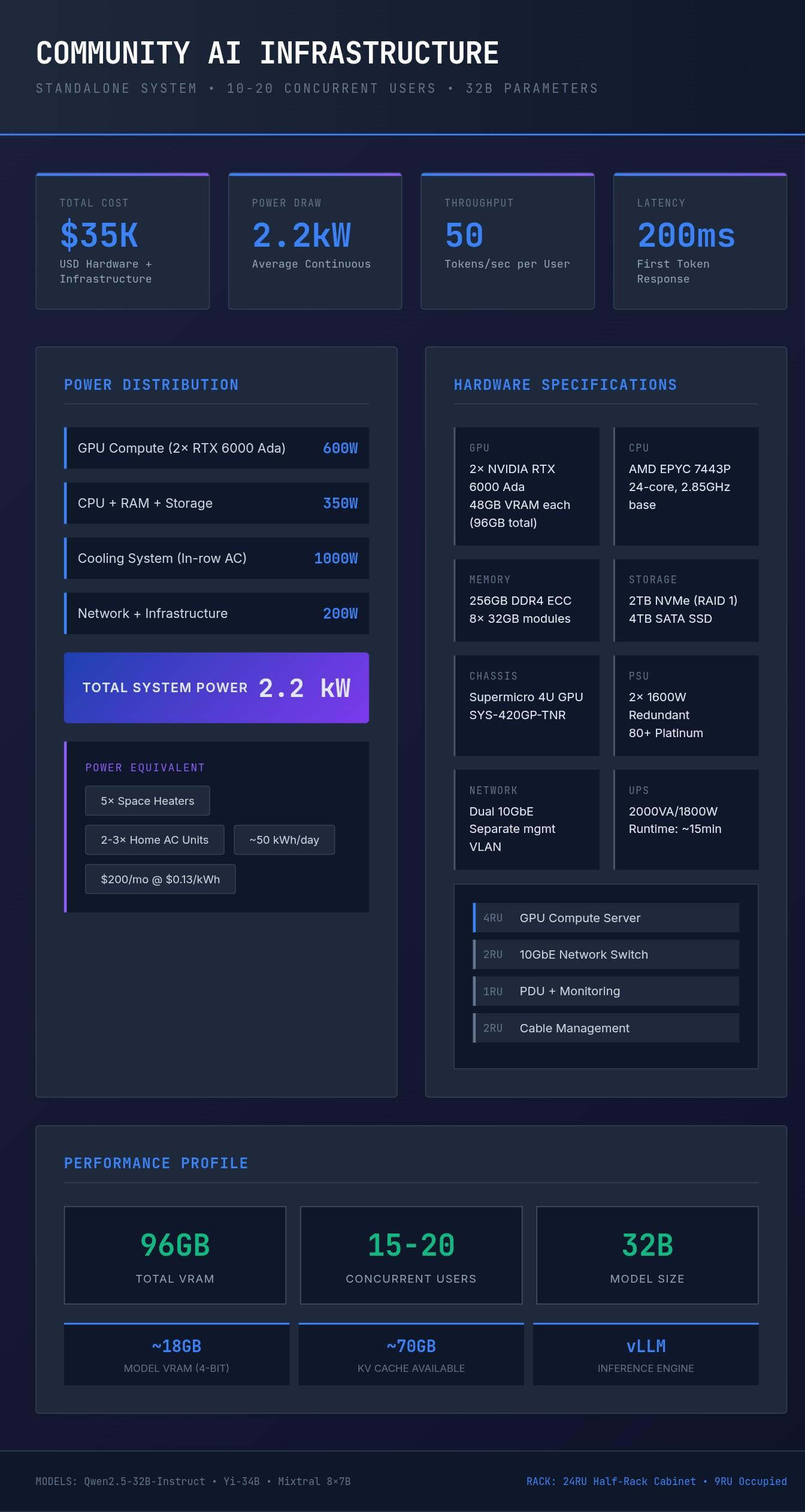
Do you hate #broligarchs?
#Billionaires? #AiSlop but still think there is merit in #AI?
Here is my proposal for a stand alone.
OFFGRID COMMUNITY AI SYSTEM.
That's right.Your very own co-op AI
The calculations are very much back of the envelope, first cut, but quite feasible.
A 32billion parameters, frontier level performance compatable open source #llm model. The power requirements is that of 3AC units including cooling. Serves 15-20 concurrent users. 40 households of 4 people each (taking into account actual AI model distributed use metrics and contention ratios)
40 households, subscribing at $30/month over 2 years + power (solar). Train with your own datasets.
Entire set up takes half a rack.
LETS GO!!!
#OpenSource #FOSS #CommunityTech #OpenHardware #EthicalAI #ResponsibleAI #AIForGood #TechForGood #Solarpunk #RegenerativeCulture #Degrowth #AppropriateTechnology #OffGrid #SelfSufficient #Homesteading #Permaculture #RightToRepair #MakerSpace #DIYTech #decentralizedtech
Introducing Slop Detective!
Interactive game where you'll become fraud investigators, learning to spot AI-generated fakes and improve fact-checking skills.
Perfect for kids learning to investigate suspicious stories, images, and audio clips:
https://slopdetective.kagi.com/
Available as apps as well!
- App Store: https://apps.apple.com/in/app/slop-detective/id6752807487
- Google Play: https://play.google.com/store/apps/details?id=com.kagi.slopdetective

Introducing Slop Detective!
Interactive game where you'll become fraud investigators, learning to spot AI-generated fakes and improve fact-checking skills.
Perfect for kids learning to investigate suspicious stories, images, and audio clips:
https://slopdetective.kagi.com/
Available as apps as well!
- App Store: https://apps.apple.com/in/app/slop-detective/id6752807487
- Google Play: https://play.google.com/store/apps/details?id=com.kagi.slopdetective
@[email protected] · Reply to Simon Willison's post
@[email protected] · Reply to Simon Willison's post
@simon “In this work, the A.I.tist explores fundamental absurdity upon infinite, grounded womanhood. The deconstruction of both the pelican itself and the bicycle frame it sits upon reflect the fragmented nature of life, and they in turn are upon wheels that cleverly combine an infinity symbol and a vagina mired waist-deep in the earth itself.”
#harvard confirms the massive impact of #AI #hiring
#junior roles ↓23%
#senior roles ↑14%
(285,000 firms monitored)
Before AI: 1 senior + 3 juniors = full team
After AI: 1 senior + AI = same output
We are creating #experts without #apprentices mentors without students. The professional ladder is losing its lowest rungs.
(Source: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=5425555 )
#FutureOfWork #Automation #AIimpact #Jobs #Productivity #WorkforceTransformation #taxai #taxtherich

#harvard confirms the massive impact of #AI #hiring
#junior roles ↓23%
#senior roles ↑14%
(285,000 firms monitored)
Before AI: 1 senior + 3 juniors = full team
After AI: 1 senior + AI = same output
We are creating #experts without #apprentices mentors without students. The professional ladder is losing its lowest rungs.
(Source: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=5425555 )
#FutureOfWork #Automation #AIimpact #Jobs #Productivity #WorkforceTransformation #taxai #taxtherich
I love local LLMs!
Here's the new #Gemma 3 270M param model running on a 2GB Rasbperry Pi 4
I love the iPhone 6(s) Plus Plus! what a great device it was
(these are always fun little things to tinker with lol)
I'm sorry... actually, no, I'm NOT sorry!
Any unsolicited presentation of ANYTHING generated using an AI/LLM WILL be met with my very audible "FUCK YOU!" and my immediate attempt to make it so that I don't have to consume it anymore. Applies to text, images, audio, whether it is the main part of the meidum or just embellishing material. FUCK. YOU.
Dear anti-AI folk: I hear you, but, please please please, complain about lacking laws and regulations, complain about the specific things you don't like, because being "against AI" is tone deaf, it doesn't arrive and it's too generic to act upon.
Whether #AI is here to stay I cannot predict, but in either case it's the boundaries we set right now that will be important for the coming decades/eons, so to actually exert control don't be against AI, be against lack of regulation and control thereof
Are you still on #Spotify?
Spotify’s CEO Daniel Ek has raised €600M for his new startup, which is developing AI TECH FOR WAR. Ek still owns 9% of Spotify, but has 37% voting control. His net worth went from $2.5B to $10B in the last two years alone, on the back of paying musicians a pittance in royalties.
And don’t forget:
• Spotify spent $250M of your subscription dollars to invite Joe Rogan to spew his disinformation on their platform.
• They’re still trying to embrace and extinguish Podcasts.
• They’re developing in-house, AI-generated “music” so users will play them (royalty-free) instead of music created by humans (who demand royalty).
And now, he’s using his wealth, created by your subscriptions, to fund tech that will use AI to literally murder humans in war.
Stop funding him. Quit Spotify now.
#QuitSpotify #music #ai #militaryTech #techbro
“Spotify’s CEO invests $1 billion into an AI military start-up — and musicians are fuming”
Are you still on #Spotify?
Spotify’s CEO Daniel Ek has raised €600M for his new startup, which is developing AI TECH FOR WAR. Ek still owns 9% of Spotify, but has 37% voting control. His net worth went from $2.5B to $10B in the last two years alone, on the back of paying musicians a pittance in royalties.
And don’t forget:
• Spotify spent $250M of your subscription dollars to invite Joe Rogan to spew his disinformation on their platform.
• They’re still trying to embrace and extinguish Podcasts.
• They’re developing in-house, AI-generated “music” so users will play them (royalty-free) instead of music created by humans (who demand royalty).
And now, he’s using his wealth, created by your subscriptions, to fund tech that will use AI to literally murder humans in war.
Stop funding him. Quit Spotify now.
#QuitSpotify #music #ai #militaryTech #techbro
“Spotify’s CEO invests $1 billion into an AI military start-up — and musicians are fuming”
Are you still on #Spotify?
Spotify’s CEO Daniel Ek has raised €600M for his new startup, which is developing AI TECH FOR WAR. Ek still owns 9% of Spotify, but has 37% voting control. His net worth went from $2.5B to $10B in the last two years alone, on the back of paying musicians a pittance in royalties.
And don’t forget:
• Spotify spent $250M of your subscription dollars to invite Joe Rogan to spew his disinformation on their platform.
• They’re still trying to embrace and extinguish Podcasts.
• They’re developing in-house, AI-generated “music” so users will play them (royalty-free) instead of music created by humans (who demand royalty).
And now, he’s using his wealth, created by your subscriptions, to fund tech that will use AI to literally murder humans in war.
Stop funding him. Quit Spotify now.
#QuitSpotify #music #ai #militaryTech #techbro
“Spotify’s CEO invests $1 billion into an AI military start-up — and musicians are fuming”
#우분투 한국커뮤니티 #20주년 함께 축하하는 축제가 될 #UbuCon #Korea 2025! 올해 UbuCon Korea의 주요 연사(Featured speaker)를 소개합니다! #사물인터넷 #콘텐츠제작 #인공지능 #클라우드 #AI #리눅스커널 #개발도구 등 다양하고 흥미로운 주제가 올해도 준비되어 있는데요, 주요 연사 분들의 세션에 꼭 참여하고 싶다면?
지금 바로 #참가등록 하고, 8월 10일 광화문 #한국마이크로소프트 에서 만나요! ...



A sort-of followup to "Show Me The Pull Requests" - https://www.linkedin.com/posts/kittylyst_ai-llms-activity-7345506506471026689-Y3nL (original post here: https://mastodon.social/@kittylyst/114397697851381604 )
Thanks to @simon for pointing me at this one. /cc @davidgerard #ai #software #softwaredevelopment #llm
요즘 영어로 메세지를 보낼일이 이래저래 많은데, 영문 작성을 위해서 AI의 도움을 많이 받고 있다. 그런데 매번 C-C & C-V 하기가 여간 귀찮은게 아니였는데, Hammerspoon을 이용하면 손쉽게 맥의 Accessibility API를 쓸 수 있단걸 떠올리고 간단히 하나 만들었다. 그리고 작성 대부분을 Vibe coding으로 해보려고 했는데 자꾸 없는 API를 쓰려 해서 결국 참고만 하고 직접 만듦. ((Vibe coder의 길은 오늘도 멀고 험난하다..))
아래 스크립트를 이용하면 입력한 텍스트를 선택하고 Cmd+Shift+K를 누르면 선택 영역을 유지한 상태로 한<->영 번역을 수행한다.
local config = {
-- OpenAI API Key
openai_api_key = "sk-proj--",
-- I'll use Response API
openai_api_url = "https://api.openai.com/v1/responses",
-- Model name
openai_model = "gpt-4o",
}
local function callOpenAI(text, callback)
if not config.openai_api_key then
hs.alert.show("Config error: missing openai_api_key")
return
end
local insturction = "입력된 문장이 영어일 경우 한국어로, 한국어일 경우 영어로 변환해줘. 의미를 모국어 사용자가 자연스럽게 받아들일 수 있게 정확하고 유창하게 전달하고, 불필요한 문장을 생략하여 명료하게 작성해. 번역어 외의 다른 문장을 추가하지 말고 번역 그 자체만 반환해."
local request = hs.json.encode({
model = config.openai_model,
instructions = insturction,
input = text,
max_output_tokens = 5000,
})
print(request)
local headers = {
["Content-Type"] = "application/json",
["Authorization"] = "Bearer " .. config.openai_api_key
}
hs.http.asyncPost(config.openai_api_url, request, headers, function(status, response, _)
if status == 200 then
local success, data = pcall(hs.json.decode, response)
if success and data.status == "completed" then
local translated = data.output[1].content[1].text
print("TR: " .. translated)
callback(translated)
else
hs.alert.show("Call failed " .. data)
callback(nil)
end
else
print(status, response)
hs.alert.show("Call failed " .. status)
callback(nil)
end
end)
end
local function getSelectedTextCB()
local orig_cb = hs.pasteboard.getContents()
print("Original Clipboard " .. orig_cb)
hs.eventtap.keyStroke({"cmd"}, "c")
local sel = hs.pasteboard.getContents()
print("Selected Text " .. orig_cb)
hs.timer.doAfter(0.1, function()
if orig_cb then
hs.pasteboard.setContents(orig_cb)
end
end)
return sel
end
local function getFocusedElement()
local ax = hs.axuielement
local sys = ax.systemWideElement()
local focused = sys:attributeValue("AXFocusedUIElement")
return focused
end
local function getSelectedTextAX()
local focused = getFocusedElement()
if not focused then
hs.alert.show("Could not found focused element")
return nil
end
local selected_text = focused:attributeValue("AXSelectedText")
if selected_text and selected_text ~= "" then
return selected_text
end
end
local function getSelectedText()
local sel = getSelectedTextAX()
if sel == nil then
sel = getSelectedTextCB()
end
return sel
end
local function replaceSelectedTextCB(new_text)
local orig_cb = hs.pasteboard.getContents()
hs.pasteboard.setContents(new_text)
hs.eventtap.keyStroke({"cmd"}, "v")
hs.timer.doAfter(0.1, function()
if orig_cb then
hs.pasteboard.setContents(orig_cb)
end
end)
end
local function replaceSelectedTextAX(new_text)
local focused = getFocusedElement()
local ran = focused:attributeValue("AXSelectedTextRange")
if ran then
local val = focused:attributeValue("AXValue")
local start_pos = utf8.offset(val, ran.location + 1)
local end_pos = utf8.offset(val, ran.location + ran.length + 1)
print(hs.inspect(val) .. "start_pos=" .. start_pos .. ", end_pos=" .. end_pos)
local new_val = string.sub(val, 1, start_pos - 1) ..
new_text ..
string.sub(val, end_pos, -1)
print(hs.inspect(new_text) .. ", " .. new_val)
focused:setAttributeValue("AXValue", new_val)
hs.timer.doAfter(0.1, function()
-- adjust cursor position
local new_ran = {location = ran.location, length = utf8.len(new_text)}
focused:setAttributeValue("AXSelectedTextRange", new_ran)
end)
return true
else
return nil
end
end
local function replaceSelectedText(new_text)
if replaceSelectedTextAX(new_text) == nil then
replaceSelectedTextCB(new_text)
end
end
hs.hotkey.bind({"cmd", "shift"}, "k", function()
local sel = getSelectedText()
if sel and sel ~= "" then
callOpenAI(sel, function(translated)
replaceSelectedText(translated)
end)
end
end)요즘 영어로 메세지를 보낼일이 이래저래 많은데, 영문 작성을 위해서 AI의 도움을 많이 받고 있다. 그런데 매번 C-C & C-V 하기가 여간 귀찮은게 아니였는데, Hammerspoon을 이용하면 손쉽게 맥의 Accessibility API를 쓸 수 있단걸 떠올리고 간단히 하나 만들었다. 그리고 작성 대부분을 Vibe coding으로 해보려고 했는데 자꾸 없는 API를 쓰려 해서 결국 참고만 하고 직접 만듦. ((Vibe coder의 길은 오늘도 멀고 험난하다..))
아래 스크립트를 이용하면 입력한 텍스트를 선택하고 Cmd+Shift+K를 누르면 선택 영역을 유지한 상태로 한<->영 번역을 수행한다.
local config = {
-- OpenAI API Key
openai_api_key = "sk-proj--",
-- I'll use Response API
openai_api_url = "https://api.openai.com/v1/responses",
-- Model name
openai_model = "gpt-4o",
}
local function callOpenAI(text, callback)
if not config.openai_api_key then
hs.alert.show("Config error: missing openai_api_key")
return
end
local insturction = "입력된 문장이 영어일 경우 한국어로, 한국어일 경우 영어로 변환해줘. 의미를 모국어 사용자가 자연스럽게 받아들일 수 있게 정확하고 유창하게 전달하고, 불필요한 문장을 생략하여 명료하게 작성해. 번역어 외의 다른 문장을 추가하지 말고 번역 그 자체만 반환해."
local request = hs.json.encode({
model = config.openai_model,
instructions = insturction,
input = text,
max_output_tokens = 5000,
})
print(request)
local headers = {
["Content-Type"] = "application/json",
["Authorization"] = "Bearer " .. config.openai_api_key
}
hs.http.asyncPost(config.openai_api_url, request, headers, function(status, response, _)
if status == 200 then
local success, data = pcall(hs.json.decode, response)
if success and data.status == "completed" then
local translated = data.output[1].content[1].text
print("TR: " .. translated)
callback(translated)
else
hs.alert.show("Call failed " .. data)
callback(nil)
end
else
print(status, response)
hs.alert.show("Call failed " .. status)
callback(nil)
end
end)
end
local function getSelectedTextCB()
local orig_cb = hs.pasteboard.getContents()
print("Original Clipboard " .. orig_cb)
hs.eventtap.keyStroke({"cmd"}, "c")
local sel = hs.pasteboard.getContents()
print("Selected Text " .. orig_cb)
hs.timer.doAfter(0.1, function()
if orig_cb then
hs.pasteboard.setContents(orig_cb)
end
end)
return sel
end
local function getFocusedElement()
local ax = hs.axuielement
local sys = ax.systemWideElement()
local focused = sys:attributeValue("AXFocusedUIElement")
return focused
end
local function getSelectedTextAX()
local focused = getFocusedElement()
if not focused then
hs.alert.show("Could not found focused element")
return nil
end
local selected_text = focused:attributeValue("AXSelectedText")
if selected_text and selected_text ~= "" then
return selected_text
end
end
local function getSelectedText()
local sel = getSelectedTextAX()
if sel == nil then
sel = getSelectedTextCB()
end
return sel
end
local function replaceSelectedTextCB(new_text)
local orig_cb = hs.pasteboard.getContents()
hs.pasteboard.setContents(new_text)
hs.eventtap.keyStroke({"cmd"}, "v")
hs.timer.doAfter(0.1, function()
if orig_cb then
hs.pasteboard.setContents(orig_cb)
end
end)
end
local function replaceSelectedTextAX(new_text)
local focused = getFocusedElement()
local ran = focused:attributeValue("AXSelectedTextRange")
if ran then
local val = focused:attributeValue("AXValue")
local start_pos = utf8.offset(val, ran.location + 1)
local end_pos = utf8.offset(val, ran.location + ran.length + 1)
print(hs.inspect(val) .. "start_pos=" .. start_pos .. ", end_pos=" .. end_pos)
local new_val = string.sub(val, 1, start_pos - 1) ..
new_text ..
string.sub(val, end_pos, -1)
print(hs.inspect(new_text) .. ", " .. new_val)
focused:setAttributeValue("AXValue", new_val)
hs.timer.doAfter(0.1, function()
-- adjust cursor position
local new_ran = {location = ran.location, length = utf8.len(new_text)}
focused:setAttributeValue("AXSelectedTextRange", new_ran)
end)
return true
else
return nil
end
end
local function replaceSelectedText(new_text)
if replaceSelectedTextAX(new_text) == nil then
replaceSelectedTextCB(new_text)
end
end
hs.hotkey.bind({"cmd", "shift"}, "k", function()
local sel = getSelectedText()
if sel and sel ~= "" then
callOpenAI(sel, function(translated)
replaceSelectedText(translated)
end)
end
end)New pre-print! #ai
**Universal pre-training by iterated random computation.**
⌨️🐒 A monkey behind a typewriter will produce the collected works of Shakespeare eventually.
💻🐒 But what if we put a monkey behind a computer?
⌨️🐒 needs to be lucky enough to type all characters of all of Shakespeare correctly. 💻🐒 only needs to be lucky enough to type a program for Shakespeare.
This suggests that passing random noise through random computation _enriches_ it. (1/n)

🆕 blog! “Why do people have such dramatically different experiences using AI?”
For some people, it seems, AI is an amazing machine which - while fallible - represents an incredible leap forward in productivity.
For other people, it seems, AI is wrong more often than right and - although occasionally useful - requires constant supervision.
Who is right?
👀 Read more: https://shkspr.mobi/blog/2025/06/why-do-people-have-such-dramatically-different-experiences-using-ai/
⸻
#AI #LLM
Critical reasoning vs Cognitive Delegation
Old School Focus:
Building internal cognitive capabilities and managing cognitive load independently.
Cognitive Delegation Focus:
Orchestrating distributed cognitive systems while maintaining quality control over AI-augmented processes.
We can still go for a jog or go hunt our own deer, but for reaching the stars we, the Apes do what Apes do best: Use tools to build on our cognitive abilities. AI is a tool.
3/3
#AI #Education #FutureOfEducation #AIinEducation #LLM #ChatGPT #Claude #EdAI #CriticalThinking #CognitiveScience #Metacognition #HigherOrderThinking #Reasoning #Vygotsky #Hutchins #Sweller #LearningScience #EducationalPsychology #SocialLearning #TechforGood #EticalAI #AILiteracy #PromptEngineering #AISkills #DigitalLiteracy #FutureSkills #LRM #AIResearch #AILimitations #SystemsThinking #AIEvaluation #MentalModels #LifelongLearning #AIEthics #HumanCenteredAI #DigitalTransformation #AIRegulation #ResponsibleAI #Philosophy

@[email protected] · Reply to AnarchoNinaAnalyzes's post
News that Trump was the tapping objectively evil Peter-Thiel affiliated contractor Palantir to help him unlock the US government's vast troves of data on everyone in the country would have been ominous at the best of times. Set against the backdrop of the Pork Reich's continued expansion of the surveillance panopticon and ongoing attempts to equate opposition to the Trump regime's agenda with terrorism however, it's downright terrifying.
https://www.ninaillingworth.com/2025/06/05/one-eye-to-see-them-all/
One Eye To See Them All
"They’re calling protestors terrorists, implying that speaking out against fascist mass deportations and a US-backed genocide is material support for terrorism, and plotting to use FARA and RICO laws to target a broadly-defined “radical left” in America. Now, the Pork Reich and one of the most amoral tech companies on Earth are teaming up to automate sorting and compiling the data Trump needs to conduct widespread repression, detainment, and ideological purges. Unless you’ve been living in a cave since Trump first strolled down that escalator to announce his presidential ambitions in late 2015, it should be pretty obvious to you that this is about more than mass deportations and fighting “terrorists.”
#Trump #Fascism #Palantir #Panopticon #PoliceState #USPol #PeterThiel #MassSurveillance #AI #Dissent #FirstAmendment
Did you know? #Fedify provides #documentation optimized for LLMs through the llms.txt standard.
Available endpoints:
Useful for training #AI assistants on #ActivityPub/#fediverse development, building documentation chatbots, or #LLM-powered dev tools.
Did you know? #Fedify provides #documentation optimized for LLMs through the llms.txt standard.
Available endpoints:
Useful for training #AI assistants on #ActivityPub/#fediverse development, building documentation chatbots, or #LLM-powered dev tools.
Did you know? #Fedify provides #documentation optimized for LLMs through the llms.txt standard.
Available endpoints:
Useful for training #AI assistants on #ActivityPub/#fediverse development, building documentation chatbots, or #LLM-powered dev tools.
This is how monopoly looks… Remember, not a single book author, artist, or FLOSS developer has ever been paid. They just used all of your data to train AI and are now making billions in profits while you struggle to buy eggs. This is why monopoly is so bad. #ai #microsoft #openai
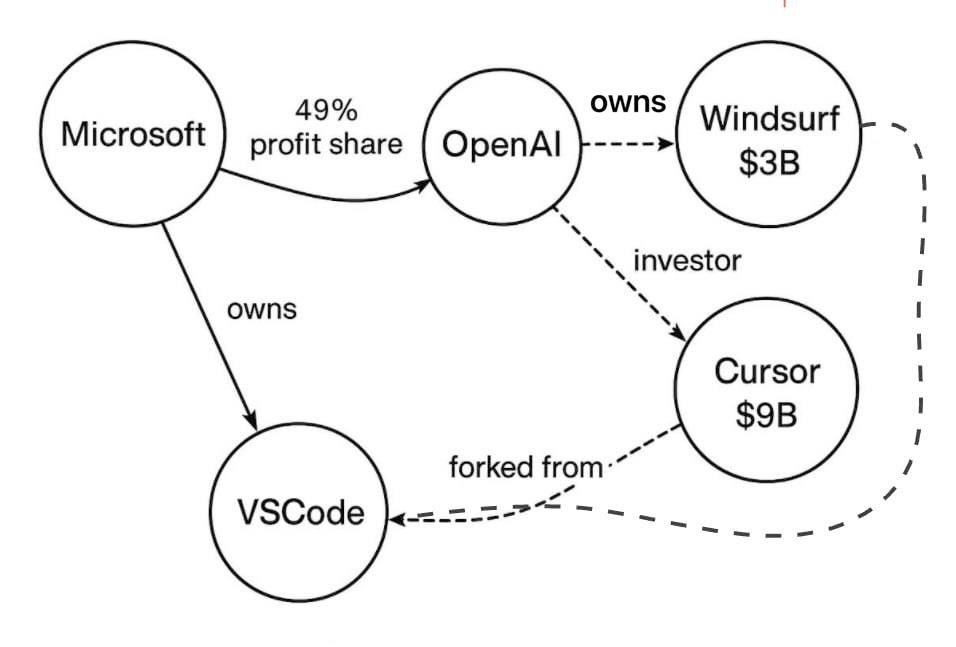
This is how monopoly looks… Remember, not a single book author, artist, or FLOSS developer has ever been paid. They just used all of your data to train AI and are now making billions in profits while you struggle to buy eggs. This is why monopoly is so bad. #ai #microsoft #openai
Last week, OpenAI CEO Sam Altman announced his ambitious plan for the World project, formerly known as Worldcoin.
https://www.privacyguides.org/articles/2025/05/10/sam-altman-wants-your-eyeball/
#Worldcoin #WorldProject #SamAltman #OpenAI #Privacy #Biometrics #Cryptocurrency #AI #PrivacyGuides #Article
Last week, OpenAI CEO Sam Altman announced his ambitious plan for the World project, formerly known as Worldcoin.
https://www.privacyguides.org/articles/2025/05/10/sam-altman-wants-your-eyeball/
#Worldcoin #WorldProject #SamAltman #OpenAI #Privacy #Biometrics #Cryptocurrency #AI #PrivacyGuides #Article
@[email protected] · Reply to Open Rights Group's post
We have the right to be presumed innocent, not predicted guilty.
Our liberties mustn't be taken away in an unjust game of probability based on flawed police data.
Sign and share our petition to BAN crime 'predicting' police tech in the UK.
ACT NOW ⬇️
https://you.38degrees.org.uk/petitions/ban-crime-predicting-police-tech
#policing #AI #precrime #justice #criminal #police #ukpol #ukpolitics #surveillance
@[email protected] · Reply to Open Rights Group's post
Crime 'prediction' police tech is how a surveillance state embeds itself into the everyday 👁️
Without committing a crime, you can be branded a threat.
Without access to redress, you can be punished.
Without transparency, you may never know how injustice happened.
We need #SafetyNotSurveillance
#policing #AI #precrime #justice #criminal #police #ukpol #ukpolitics #surveillance
@[email protected] · Reply to Open Rights Group's post
'Predictive' policing systems can lead to unjust stop-and-search in an effective digital sus law.
Joint enterprise is already used to bring conspiracy charges against people who've committed no crime.
And then there's the UK's chilling Homicide Prediction Project 🤯
#policing #AI #precrime #justice #criminal #police #ukpol #ukpolitics #surveillance
@[email protected] · Reply to Open Rights Group's post
Police tech 'predicts' crime by location or individual 🤖
"Crime hotspots" targets poorer neighbourhoods, while "gang" or "gang-affiliated" are a dog whistle for young Black men and boys.
People are criminalised for where they live, who they hang out with, or for matching a biased data profile.
#policing #AI #precrime #justice #criminal #police #ukpol #ukpolitics #surveillance
@[email protected] · Reply to Open Rights Group's post
Algorithms that claim to 'predict' crime are only as 'objective' as the data they're fed.
With crime data reflecting decades of racist and discriminatory policing, the tech will just say to deploy resources in the same way.
It becomes a self-fulfilling feedback loop.
Bad Cops: Rinse and Repeat.
#policing #AI #precrime #justice #criminal #police #ukpol #ukpolitics #surveillance
Outlook not so good 🎱
Police tech doesn’t predict crime. It predicts policing.
Based on biased data, it brings more of the same – racist policing and poverty punishment.
Read our latest blog on why crime 'predicting' police tech must be BANNED ⬇️
https://www.openrightsgroup.org/blog/why-predictive-policing-must-be-banned/
#policing #AI #precrime #justice #criminal #police #ukpol #ukpolitics #surveillance
Show me the Pull Requests.
I keep hearing #AI boosters / talking heads claiming that #LLMs have transformed software development, "it's not just about prototyping - AI is writing solid production code", etc.
So here's a challenge:
Share some AI-derived pull requests that deal with non-obvious corner cases or non-trivial bugs from mature #opensource projects. I'll also accept high-quality documentation that isn't just the sort of wasted space & slop that I always tell juniors not to write.
Join @ishotjr and a panel of special guests as we explore the world of humanoid #robots! We show you how to use #AI and #OpenSource to build #bots from #humanoid heads to four-legged friends! Register now for our Thursday, May 15th V93 #LaunchParty! 🥳

@[email protected] · Reply to AnarchoNinaAnalyzes's post
In an early March announcement that was underreported at the time (but just became a lot more relevant in early April) the Trump regime revealed its intention to collect and presumably monitor social media handles of folks applying to legally work and reside in the United States:
https://theintercept.com/2025/03/23/trump-immigrants-social-media-citizenship-green-card/
Trump Wants Immigrants on U.S. Soil to Hand Over Social Media Accounts to Apply for Citizenship
"Collecting social media information, according to the USCIS proposal first posted March 5, is necessary “for the enhanced identity verification, vetting and national security screening.”
The proposal specifically cites Trump’s January 20 executive order, which advocates have warned goes well beyond the Muslim travel ban from Trump’s first term, which targeted people living abroad.
The new executive order stated that “the United States must ensure that admitted aliens and aliens otherwise already present in the United States do not bear hostile attitudes toward its citizens, culture, government, institutions, or founding principles, and do not advocate for, aid, or support designated foreign terrorists and other threats to our national security.”
USCIS said the social media handles it collects would be used to determine if people applying for a variety of immigration statuses pose a “security or public-safety threat.”"
Of course, observers immediately noted the connection between this proposed policy and Trump's ideological policing, kidnaping, and attempted deportation of foreign students who participated in anti-Genocide protests and/or oppose the Trump regime:
"In light of Columbia University protester Mahmoud Khalil’s ongoing detention, one official from a Muslim civil rights group said the new policy poses special danger for critics of Israel and the Trump administration.
“This policy would disparately impact Muslim and Arab applicants seeking U.S. citizenship that have voiced support for Palestinian human rights,” said Robert McCaw, director of government affairs at the Council on American-Islamic Relations. “Collecting the social media identifiers of any potential green card applicants or citizens is the means to silencing their lawful speech.”
Furthermore, as a representative of the EFF presciently observed, there are few if any limits on the scope of what the government can do with this data if they get it, and modern AI technology allows for the regime to ideologically police and target a terrifying number of people who oppose our fascist overlords. It's also, strictly speaking, a violation of Constitutional rights:
"The policy proposal does not sketch out limits on how USCIS can use its newly acquired data, according to Saira Hussain, a senior staff attorney at the Electronic Frontier Foundation.
Hussain said she was particularly concerned that the government might use artificial intelligence or other automated tools to punish speech it dislikes, pointing to a news report that the State Department is using AI to revoke the visas of people who allegedly express “pro-Hamas” sentiments.
Hussain said she feared a chilling effect, where people applying for a change in status refrain from speaking about potentially controversial issues.
“Anybody who is within the bounds of the United States has First Amendment rights,” she said. “The Constitution applies whether you are somebody who is a citizen or somebody who is a green card holder who is here in the United States. I think that this administration is trying to chip away at that notion, but that is very much what First Amendment jurisprudence has been under the courts.”
Finally, it should be pointed out that the regime's proposal gives no indication whatsoever of when the government would stop recording and monitoring the social media activities of the people it's targeting:
"CAIR’s McCaw said he worried that the policy could be used to continue tracking people’s activity on social media even after they become naturalized citizens.
“There’s no clear sign on when this intrusion into our electronics and communications will end,” he said."
#Fascism #DHS #ICE #Trump #AI #WhiteNationalism #SocialMedia #OnlineSurveillance #Immigration #MigrantRights #Islamophoba #Palestine #Genocide #PoliceState #McCarthyism #USCIS #Nativism
Thank you #PyConAPAC #PyConPH for giving me to opportunity to talk about things that is close to my heart: #AI #A11y #Diversity and #Inclusion

Thank you #PyConAPAC #PyConPH for giving me to opportunity to talk about things that is close to my heart: #AI #A11y #Diversity and #Inclusion
 🌺🎗️
🌺🎗️>ai가 가치중립적일것이라 생각하는 사람들이 생각보다 많아서 놀라움..ai가 사용하는 데이터 자체가 이 불평등한 구조 하에서 끊임없이 기득권층에게 유리한 방향으로 재생산 되며 수백년동안 축적되어온것인데..
https://x.com/andfldrh/status/1893478385105428762
#ai
@[email protected] · Reply to Artist Activist's post
#SaudiArabia’s $100B #ProjectTranscendence, marks a significant push by the Kingdom to develop a robust #AI ecosystem that can rival leading tech hubs, including neighbouring #UnitedArabEmirates and other global technology centers.
https://www.cio.com/article/3602900/saudi-arabia-launches-100-billion-ai-initiative-to-lead-in-global-tech.html
#Salesforce #ArtificialIntelligence #Amazon #AWS #Riyadh #USA #Trump #Musk #GCC #Saudi #UAE #DOGE #coup
@[email protected] · Reply to Artist Activist's post
#Salesforce has announced a $500 million investment in #ArtificialIntelligence initiatives in #SaudiArabia, and will deploy its Hyperforce platform there through a strategic partnership with #Amazon Web Services (#AWS). Additionally, the company plans to establish a regional headquarters in #Riyadh.
https://www.nasdaq.com/articles/salesforces-crm-500m-saudi-investment-fuels-global-ai-growth
#USA #AI #ProjectTranscendence #Trump #UnitedArabEmirates #Musk #GCC #Saudi #UAE #DOGE #coup
@[email protected] · Reply to Artist Activist's post
#Salesforce announced this week that it’s planning $500 million of AI-related investments in #SaudiArabia. Like the #USA, Saudi Arabia—a major oil and gas exporter—is looking to capitalize on its abundance of wealth and fossil fuels to become an #AI superpower, including in a $100 billion initiative called #ProjectTranscendence.
https://newrepublic.com/article/191506/musk-bezos-pichai-zuckerberg-microsoft-trump-climate
#Trump #UnitedArabEmirates #Musk #GCC #Saudi #SaudiArabia #UAE #DOGE #coup
Ich habe meinen #38c3 Talk über den Ressourcenverbrauch von #AI mal
auf Deutsch aufgeschrieben.
"Ressourcenverbrauch von AI
Oder: wie AI uns wirklich umbringen wird"
https://thomasfricke.de/post/energy-resource-ai-de/
Der Talk ist hier
https://media.ccc.de/v/38c3-resource-consumption-of-ai-degrow-or-die
Der #degrowth Teil kommt in einem extra Artikel. Wer inhaltliche Fehler findet,
bitte Bescheid sagen! Auch sprachlich ist noch Luft nach oben.
@bitsundbaeume @bitsundbaeume_berlin @SheDrivesMobility @mfeilner @fff @parents4future @S4F @Fischblog
📢 I'm now available for keynote talks worldwide 🌐
* How to use ‘Economies of Empowerment’ to get the benefits of both speed and scale
* the AI-savvy operating model
* Platform Engineering done well: innovation, efficiency, market advantage
Request a keynote via https://matthewskelton.com/keynotes

@[email protected] · Reply to khobochka's post
@khobochka We need an international co-operative system of making these parties pay for scraping. It includes legislative changes. At the same time it can become a real-time pricing market for ”rights to scrape” and for creators to get paid.
Here’s my whitepaper for a solution. Absolutely no cryptocurrency involved.
#ai #scraping #copyright #technology #whitepaper
https://docs.google.com/document/d/18cz-ZX1copCYiC4C2ReY8GLJjuhG2IH0MEBGaoSJhP4/edit
I am kinda on the Karmic side of #infotech
If you were lazy ok with corps eating all your data because #privacy was not your concern.
Or worse, were one of those Muppets who espoused "I have nothing to hide, so I have nothing to fear" and accepted ubiquitous #surveillance from your Government without any action on your part...
...you absolutely have no leg to stand on and get all squeally about #ai #generative #llm eating all your precious doodles and unpublishable writings you blogged.
You allowed this to happen by your inaction.
Just because you were unequipped to see the consequences, you were happy to abandon us, who tried to hold the thin red line against the #dataabuse.
I looked over my shoulder, and there was no one behind us.
These things do not happen overnight and if we had strong regulatory regime, we would not be here now.
Instead the public stampeded into the cloud and big data like farm animals to slaughter.
"First they came for the hackers, and I did not speak out—because I was not a hacker.
Then they came for the file sharers, and I did not speak out—because I was not sharing mp3s.
Then they came for the Indy web zines, and I did not speak out—because I was not an Indy web zines reader.
Then they came for the porn, and I did not speak out—because I was not using porn.
Then they came for my socials, and I did not speak out—because techbros bring capital and I love doom scrolling.
Then they built huge, city sized, five eyes, surveillance data centres in the desert, and I did not speak out—because I had nothing to hide.
Then they built Netflix and all the streaming data centres, and I did not speak out—because everyone loves to Netflix and chill binge.
Then they put everything into the cloud; data centres, and I did not speak out—because I don't really understand other people's computers and cloud is cool.
Then the AI came for my job, devoured all the knowledge, boiled the rivers and burned the land—and there was nowhere left to speak for me."
- "Dead Internet" by Wulfy,
with sincere apologies to
— Martin Niemöller (Lutheran pastor in (Nazi) Germany - 1892 - 1984)
#ai #techbros #deadinternet #freespeech #surveillance #hackers
It's really effing obvious LLMs are a con trick:
If LLMs were actually intelligent, they would be able to just learn from each other and would get better all the time. But what actually happens if LLMs only learn from each other is their models collapse and they start spouting gibberish.
LLMs depend entirely on copying what humans write because they have no ability to create anything themselves. That's why they collapse when you remove their access to humans.
There is no intelligence in LLMs, it's just repackaging what humans have written without their permission. It's stolen human labour.
I don't know who cares to hear this, but I publicly pledge to never use generative #AI to do any of my writing.
That means no AI to generate ideas, generate words, or edit my writing.
(It does not mean I won't use tools to learn how they work for purposes of criticism.)
Last night I came up with (and implemented!) an idea for a mastodon client that automatically curates my feed by categorizing toots. It's just idea phase right now, but I wrote about the process here https://timkellogg.me/blog/2023/12/19/fossil #LLMs #AI #feditips
Automate the boardroom before the factory floor.
Ignore the fact we could replace most executives with a #d20 dice. Even the best ones could be automated easier than building complex #robots and #software to replace jobs that are inexpensive.
Or your class in #DnD will forever be "traitor"
#introduction #it #tech #technology #politics #ai #llm #machinelearning #engineering #technik #management #labor #leftist #mastodon #workers #alttech #foss #fediverse #europe #eu #europa #germany #france

Hi everyone! Six more months passed since my last #introduction, so here is an updated one:
AKA: +mala, AiTTaLaM
Job: Doin’ trustworthy #AI @ moz://a.ai - more generally I love #teaching, no matter if to humans or machines :-)
Projects: 3564020356.org is the oldest (~22yrs 😅), #PicoGopher the most recent... Look around and find the rest! 😜
Interests: #bouldering #gopher #SelfHosting #opensource #reversing #fediverse #recsys #ML #solarpunk #CommunitiesOfExperience





Hi all! I'm Joseph Szymborski, a #PhD student at McGill university studying #deeplearning models as applied to molecular biology.
Specifically, I'm working on predicting the interaction of proteins based solely on their amino acid sequence.
Follow for upcoming blog posts on topics related to #bioinformatics , molecular biology, and other generally nerdy things.
Eager to meet and share ideas with #compbio #netbio and #deeplearning people here!
@[email protected] · Reply to Simon Willison's post
(1/n)
#ArtificialGeneralIntelligence (#AGI) has a 10% probability of causing an Extinction Level Event for humanity (1)
Thanks for this additional piece of information, Simon.
It reminded me that I had wanted to add a word in my toot: indelibly.
As any #SciFi aficionado will tell you:
👉there should be a built-in self-destruct mechanism when tampering with these Laws or copying or moving the #AI to another system.👈
Another classic movie comes to mind in this respect, #Wargames...

@[email protected] · Reply to HistoPol (#HP) 🏴 🇺🇸 🏴's post
This #toot deserves A LOT more attention.
#ChatGPT has seemingly #apocalytic tendencies.
If U aren't a #Ludite, U will at least consider becoming one afterwards.
#SkynetAntePortas
#TheMatrix might be imminent.
Have all these #AI engineers @ #OpenAI never read #IsaacAsimov? Seen #TheMatrix franchise?
How could they NOT implement the #ThreeLawsOfRobotics +, in particular, the #ZerothLaw *indelibly* into the #AI?!?

The Expanding Dark Forest and Generative AI
Proving you're a human on a web flooded with generative AI content
https://maggieappleton.com/ai-dark-forest
#GenArt #GenerativeArt #AIart #AI #DarkForest #CozyWeb #DarkWeb #HumanContent #ContentGeneration #News

#introduction Hi I'm Richard and I'm looking for a new type of social media. Something akin to the blogosphere in 2004. I'm an old-school tech blogger, started a site called ReadWriteWeb in 2003 and then chronicled the Web 2.0 era on it.
I'm currently writing a book (#nonfiction #techhistory); at least 500 words per day, usually very early in the morning.
I'm a #type1diabetic #T1D
My current interests:
#webdev
#fediverse
#AI
#InternetHistory
#11ty
#electronicmusic
#literature
Learning #Mastodon etiquette: so a short Introduction: I do research on #media, #journalism, #polcomm, #AI, #digital #tech, #politics and #democracy. I am based at U #Amsterdam and also direct the Digital Democracy Centre at U Southern Denmark. My interests are (too) broad, I am impatient, score high on #badhumor, energetic and generally optimistic. I am here to learn, frustrate Elon, and I will post mostly about work, but with occasional #dogsofmastodon, #running, and irrelevant photo content.
#introduction (reposted from old profile)
Gen-Xer born in #Mexico; since kid I was a #computer #nerd and liked #anime and #scifi, so it was logical I'd eventually discover the #cyberpunk genre (#ghostintheshell, #akira, #neuromancer, #bubblegumcrisis, #parasitedolls, #lain...)
Aside from that I've done #opensource and #freesoftware; have gnu/#Linux on my PC and recently I discovered #decentralization.
Currently #amwriting a scifi novel about #AI and #androids.